
「この画像は猫か、犬か?」「このメールはスパムか、否か?」 私たちの身の回りでは、AI(人工知能)が様々な「分類」タスクで活躍しています。でも、AIはどうやってこれほど賢くデータを分類しているのでしょうか? その秘密の一つが、今回ご紹介するサポートベクターマシン(SVM: Support Vector Machine)というアルゴリズム、そしてその中核をなす「マージン最大化」という考え方です。
AIや機械学習の基本的なコンセプトはご存知の方も多いかと思いますが、「SVMやマージン最大化はちょっと自信がない…」「G検定に向けて理解を深めたい!」という方もいらっしゃるでしょう。この記事では、そんなあなたのために、
- SVMがどのように「境界線」を引いてデータを分類するのか
- 「マージン最大化」とは何か、なぜ重要なのか
- データの種類に応じたSVMのアプローチ(ハードマージン vs ソフトマージン)
- 複雑なデータも扱える「カーネルトリック」という魔法
- マージン最大化を理解するメリットとG検定でのポイント
などを、図のイメージや具体例、簡単なコード例も交えながら、できるだけ分かりやすく解説していきます。この記事を読めば、あなたもマージン最大化の概念を自信を持って説明できるようになり、SVMの仕組みへの理解が深まるはずです!
サポートベクターマシン(SVM)と「境界線」の考え方
まずは基本から。SVMは、主に分類問題(データをグループ分けする問題)で強力な性能を発揮する教師あり学習アルゴリズムの一つです。回帰問題(数値を予測する問題)にも使えますが、特に分類でその真価を発揮します。
SVMの基本的なアイデアは非常にシンプルです。それは、異なるクラス(グループ)のデータを最も上手く分離する「境界線」を見つけることです。
なぜ「境界線」を引くことが重要なのか?
想像してみてください。平面上に赤色の点と青色の点が散らばっているとします。この2つのグループを分けるには、どうすれば良いでしょうか? きっと、多くの人は赤色の点と青色の点の間に一本の線を引くことを考えるでしょう。
この「線」が、SVMでいう決定境界(Decision Boundary)です。2次元データなら直線ですが、データが3次元なら平面、さらに高次元なら超平面(Hyperplane)と呼ばれるものになります。(難しく考えず、ここでは「データを分ける境界」くらいのイメージでOKです!)
この境界線を基準にして、新しいデータがどちらのクラスに属するかを判断するわけです。だから、できるだけ「良い」境界線を見つけることが、正確な分類のためには非常に重要なのです。
マージン最大化とは?~最も安全な境界線を求めて~
では、SVMにとって「良い」境界線とは何でしょうか? データを分けられる境界線は無数に引けそうですが、SVMはその中でも最も安全な境界線を選ぼうとします。ここで登場するのが「マージン最大化」の考え方です。
マージンの定義:境界線からの「安全地帯」
マージン(Margin)とは、決定境界と、その境界線に最も近いデータ点との間の距離のことです。イメージとしては、決定境界の両側に設ける「緩衝地帯」や「安全地帯」のようなものです。
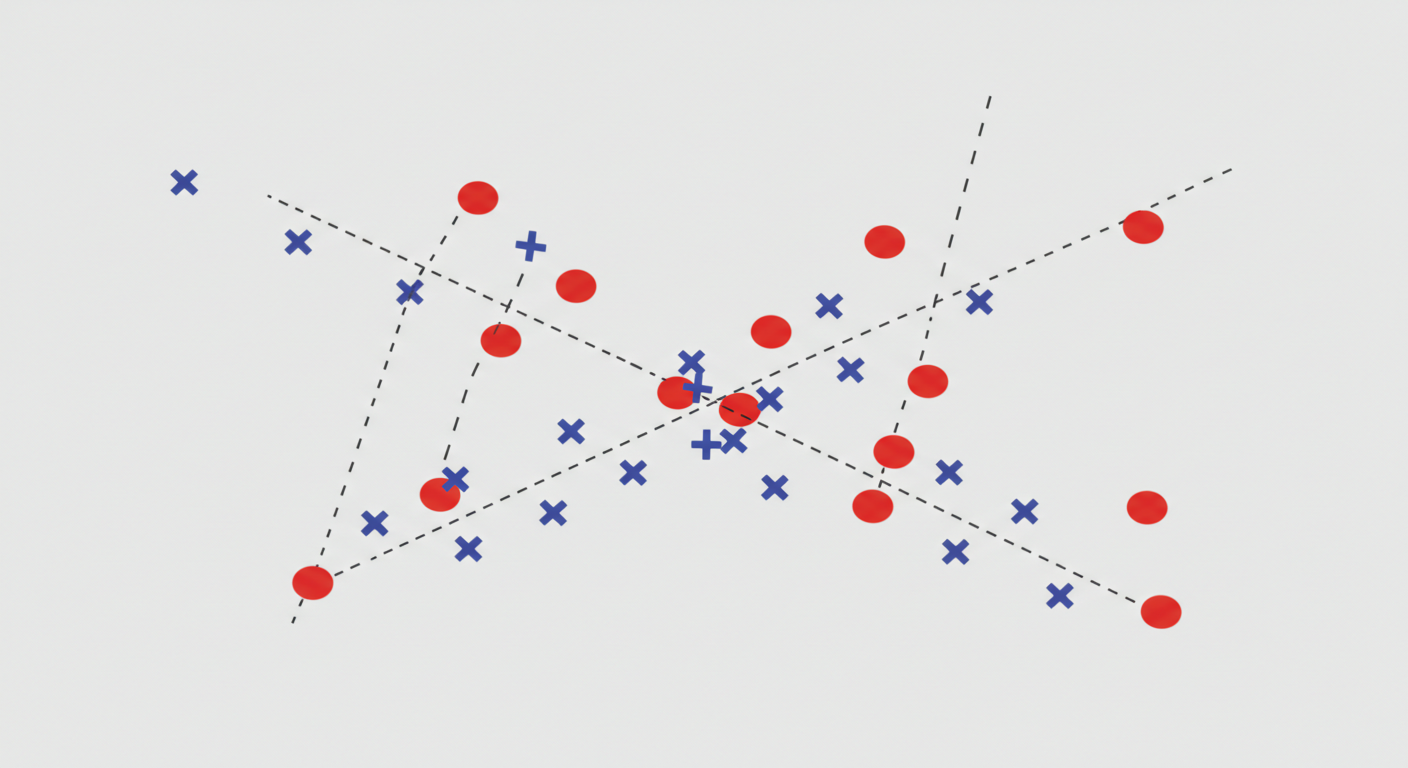
SVMは、このマージンの幅が最大になるように決定境界を引きます。これがマージン最大化です。
なぜマージンを最大化すると良いのでしょうか? 直感的には、境界線がどちらかのクラスのデータ点にギリギリすぎると、少しデータがズレただけで誤分類してしまう危険性が高まりますよね。マージンが大きいということは、境界線が各クラスの最も近い点から十分に離れていることを意味し、未知の新しいデータが来たときにも、より安定して正しく分類できる可能性が高まる(=汎化性能が高い)と考えられるからです。
サポートベクター:境界線を支える重要な点
マージンを決める上で非常に重要な役割を果たすのが、サポートベクター(Support Vector)です。これは、決定境界に最も近いデータ点のことを指します。まさに、マージン境界線上に乗っかっている点たちのことです。
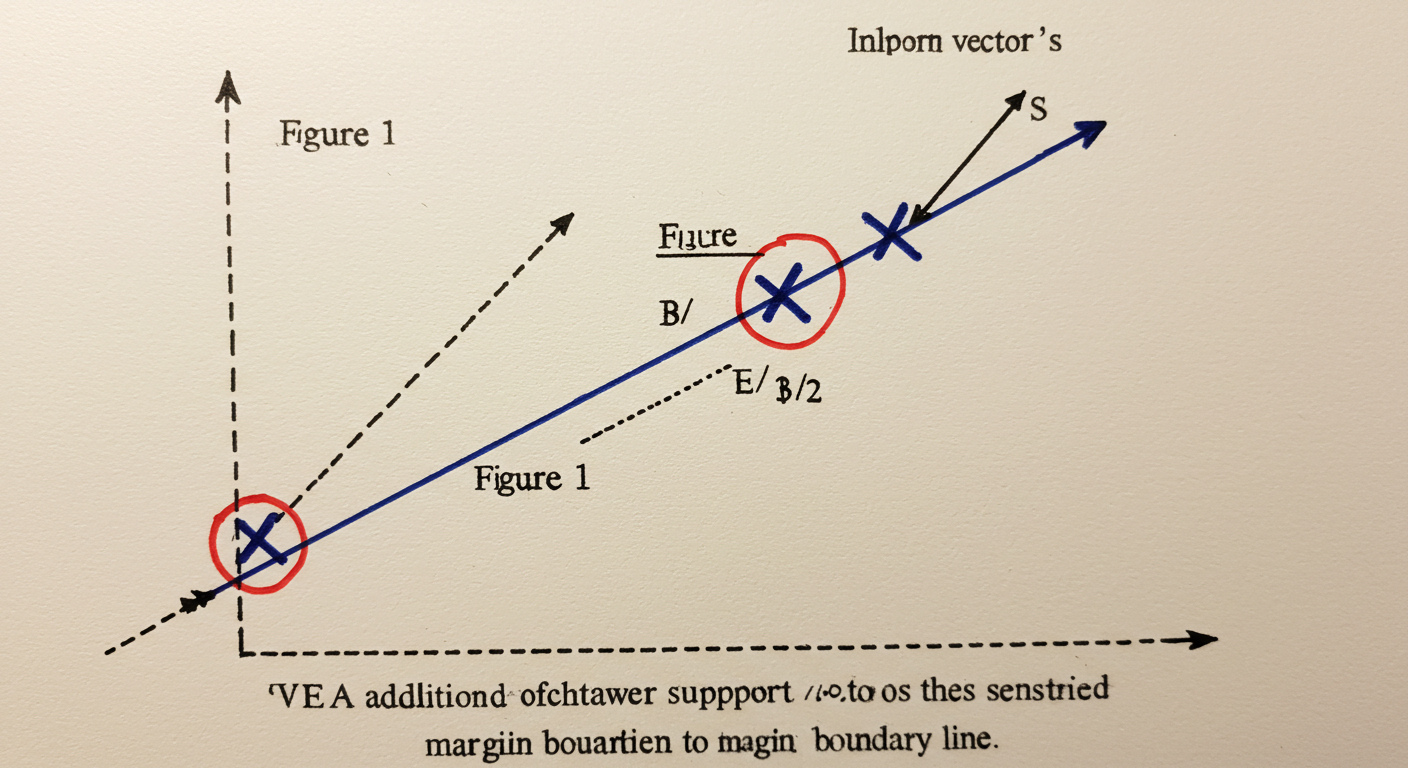
面白いことに、SVMの決定境界は、このサポートベクターの位置だけによって決まります。他のデータ点が多少動いても、サポートベクターが変わらなければ決定境界は変化しません。まさに、境界線を「支える(Support)」ベクトル(点)というわけです。
少し数式にも触れておきましょう。決定境界は一般的に wTx+b=0 という式で表されます(w は法線ベクトル、b はバイアス項、x はデータ点)。そして、サポートベクターは、マージン境界である wTx+b=1 または wTx+b=−1 の上に存在するように決められます。
マージン最大化の数学的表現(少しだけ詳しく)
マージン最大化は、数学的にはどのように表現されるのでしょうか? 先ほどのマージン境界 wTx+b=1 と wTx+b=−1 の間の距離(マージンの幅)は、実は ∣∣w∣∣2 と計算できます(∣∣w∣∣ はベクトル w の大きさ(ノルム)を表します)。
マージン幅 ∣∣w∣∣2 を最大化したいということは、分母である ∣∣w∣∣ を最小化すれば良い、ということになりますね。(計算を簡単にするため、通常は ∣∣w∣∣ の代わりに 21∣∣w∣∣2 を最小化します。結果は同じです。)
つまり、SVMのマージン最大化は、以下の最適化問題として定式化されます。
- 目的: 21∣∣w∣∣2 を最小化する
- 条件: すべてのデータ点 xi について、yi(wTxi+b)≥1 を満たす (yi はクラスラベルで +1 または -1)
この条件は、「すべてのデータ点が、自分のクラス側のマージン境界線上、またはそれよりも外側に正しく分類されていること」を意味しています。
現実は甘くない?ハードマージン vs ソフトマージン
さて、先ほどの最適化問題は、すべてのデータがマージン境界の外側にきれいに分類できる、という理想的な状況を仮定しています。これをハードマージンSVMと呼びます。
ハードマージン:一切の誤分類を許さない完璧主義
ハードマージンSVMは、その名の通り「厳格」です。一つも誤分類を許さず、すべてのデータ点がマージン領域の外側にあることを要求します。
このアプローチは、データが完全に線形分離可能(一本の直線や平面でスパッと分けられる)な場合には有効です。しかし、現実のデータはそう単純ではありません。
ハードマージンの問題点は、
- データが少しでも混ざり合っていたり、ノイズが含まれていたりすると、条件を満たす境界線を見つけられない。
- 外れ値(Outlier)(他のデータから大きく離れた点)に非常に敏感。たった一つの外れ値のために、マージンが極端に狭くなったり、境界線の向きが大きく変わってしまったりする。
ということです。これでは実用上、使いにくい場面が多くなってしまいます。
ソフトマージン:多少の誤りは許容する現実主義
そこで登場するのがソフトマージンSVMです。こちらは、ハードマージンの厳格な条件を少し「ソフト」にして、ある程度のマージン違反(マージン内への侵入)や誤分類を許容するアプローチです。
これを実現するために、スラック変数(Slack Variable) ξi (グザイ・アイと読みます) というものを導入します。これは、各データ点 xi がどれだけマージン条件を違反しているかを表す「緩み」の度合いです。ξi=0 なら違反なし、ξi>0 ならマージン内への侵入や誤分類があることを示します。
ソフトマージンSVMの最適化問題は以下のようになります。
- 目的: minw,b,ξ21∣∣w∣∣2+C∑i=1nξi
- 条件: すべてのデータ点 xi について、yi(wTxi+b)≥1−ξi かつ ξi≥0
目的関数に注目してください。第1項 21∣∣w∣∣2 は従来通りマージン最大化(∣∣w∣∣最小化)を目指す項です。そして第2項 C∑ξi が新たに追加されました。これは、マージン違反の合計量(∑ξi)にペナルティを与える項です。
ここで登場する C はハイパーパラメータ(人間が調整するパラメータ)で、非常に重要です。
- C が大きい: マージン違反へのペナルティが重くなるため、誤分類をできるだけ減らそうとします。結果としてハードマージンに近い、狭いマージンの境界線になりがちです。
- C が小さい: マージン違反へのペナルティが軽くなるため、多少の誤分類を許容してでも、マージンを広く取ろうとします。
この C を調整することで、マージン最大化と誤分類許容度のトレードオフをコントロールし、データの特性に合わせて最適なモデルを見つけることができます。現実世界の多くの問題では、このソフトマージンSVMが使われています。
線形分離できないデータはどうする?魔法の「カーネルトリック」
ハードマージン、ソフトマージンについて学びましたが、これらは基本的にデータが直線(または超平面)で分離できる、あるいは多少の誤分類を許せば分離できる、という前提がありました。しかし、データが複雑に入り組んでいる場合はどうでしょうか?

このような線形分離不可能なデータに対して、SVMはどのように対処するのでしょうか? ここで登場するのが、非常に巧妙なテクニックであるカーネルトリック(Kernel Trick)です。
カーネルトリックの発想:次元を増やして分離しやすくする
カーネルトリックの基本的なアイデアは、「元の次元で分離できないなら、もっと高い次元の空間にデータを写像(変換)して、そこで分離すれば良いじゃないか!」というものです。
先ほどのドーナツ状のデータ(図4)を例に考えてみましょう。これは2次元平面上では直線で分離できません。しかし、これを例えば3次元空間にうまく写像して、Z軸方向に赤丸を上に、青バツを下に動かすことができれば、3次元空間内のある平面でスパッと分離できるようになるかもしれません。
これがカーネルトリックの発想です。元の特徴量 x から、新しい特徴量 ϕ(x) を持つ高次元空間へとデータを変換(写像)します。
しかし、実際にデータを高次元空間に写像して計算するのは、計算量が爆発的に増えてしまう可能性があります(特に非常に高い次元、あるいは無限次元を考える場合)。そこで「トリック」が登場します。
カーネル関数:内積計算の代わり
SVMの最適化問題を解く際には(特に後述する双対問題)、データ点同士の内積(Dot Product) xiTxj という計算がたくさん出てきます。カーネルトリックの素晴らしい点は、実際に高次元空間へデータを写像しなくても、高次元空間での内積 ϕ(xi)Tϕ(xj) を、元の次元のデータ xi,xj だけを使って計算できる特別な関数、カーネル関数 K(xi,xj) を使う点にあります。
つまり、K(xi,xj)=ϕ(xi)Tϕ(xj) を満たすカーネル関数 K があれば、わざわざ ϕ(x) を計算しなくても、元のデータ xi,xj から直接、高次元空間での内積に相当する値が得られるのです。これにより、計算コストを抑えたまま、高次元空間での線形分離を実現できます。これが「トリック」と呼ばれる所以です。
代表的なカーネル関数には以下のようなものがあります。
- 線形カーネル(Linear Kernel): K(xi,xj)=xiTxj
- これは実質的にカーネルを使わない、通常の線形SVMと同じです。
- 多項式カーネル(Polynomial Kernel): K(xi,xj)=(γxiTxj+r)d
- データの特徴量の交互作用を考慮した、非線形の境界線を引くことができます。d は次数。
- RBFカーネル(ガウシアンカーネル): K(xi,xj)=exp(−γ∣∣xi−xj∣∣2)
- Radial Basis Function Kernel の略。非常に柔軟な決定境界を作ることができ、最もよく使われるカーネルの一つです。データ点間の距離に基づいて類似度を測ります。γ は影響範囲を調整するパラメータ。
- シグモイドカーネル(Sigmoid Kernel): K(xi,xj)=tanh(γxiTxj+r)
- ニューラルネットワークの活性化関数に似た形をしています。
どのカーネル関数を選択するか、そしてそのパラメータ(d, γ, r など)をどう設定するかは、データの性質によって異なり、試行錯誤が必要な部分です。
なぜカーネルトリックが SVM と相性が良いのか?
SVMの最適化問題を解く際には、計算効率などの理由から、元の問題(主問題)を双対問題(Dual Problem)という形に変形して解くことがよくあります。(ここでは詳細な導出は省略しますが、ラグランジュ乗数法という手法を使います。)
この双対問題の目的関数は、以下のような形になります(ソフトマージンの場合)。
maxα∑i=1nαi−21∑i=1n∑j=1nαiαjyiyjK(xi,xj) (制約条件: 0≤αi≤C, ∑i=1nαiyi=0)
ここで αi はラグランジュ乗数と呼ばれる変数です。重要なのは、この式の中でデータ点が K(xi,xj) というカーネル関数の形(=内積の形)でしか現れないということです。そのため、カーネル関数を差し替えるだけで、簡単に様々な非線形な決定境界を持つSVMを実装できるのです。これが、SVMとカーネルトリックの相性が抜群に良い理由です。
マージン最大化の意義とメリット
ここまでSVMとマージン最大化の仕組みを見てきましたが、この考え方にはどのような意義やメリットがあるのでしょうか?
高い汎化性能:未知のデータに強いモデルを作る
マージン最大化の最大のメリットは、やはり未知のデータに対する高い汎化性能が期待できる点です。
- 決定境界の安定性: マージンが大きいということは、決定境界がデータ点の密集地帯から離れていることを意味します。これにより、訓練データにノイズが多少含まれていたり、新しいデータが少し変動したりしても、境界線が大きく揺らぐことなく安定しやすくなります。
- 過学習(Overfitting)の抑制: SVM、特にマージン最大化は、訓練データに完璧に適合しすぎること(過学習)を防ぐ効果があります。決定境界は少数のサポートベクターによって決まるため、他の多くのデータ点の影響を受けにくく、モデルが複雑になりすぎるのを抑えます。
- 構造的リスク最小化(SRM): これは少し専門的ですが、マージン最大化は構造的リスク最小化(Structural Risk Minimization)という考え方を実現する一例とされています。これは、単に訓練データでの誤差(経験リスク)を最小化するだけでなく、モデルの複雑さ(VC次元などで測られる)も同時に考慮し、そのバランスを取ることで、真の汎化誤差(未知データでの誤差)を小さくしようとする考え方です。マージン最大化は、モデルの複雑さを抑えつつ、データへの適合を目指す点でSRMの思想に合致しています。
他の機械学習手法への影響
マージン最大化の考え方はSVM特有のものですが、「クラス間の分離をできるだけ明確にする」という発想は、他の機械学習アルゴリズムにも影響を与えています。例えば、アンサンブル学習のBoosting(特にAdaBoostなど)や、ニューラルネットワークにおける正則化の手法にも、マージンの概念と関連する考え方を見ることができます。
Python (scikit-learn) で SVM を試してみよう(コード例)
理論だけでなく、実際にSVMがどのように使われるのか、Pythonの有名な機械学習ライブラリ scikit-learn を使った簡単なコード例を見てみましょう。ここでは、アヤメ(iris)のデータセットを使って、2つの特徴量から品種を分類する例を示します。(詳細なコード解説は割愛します)
Python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.inspection import DecisionBoundaryDisplay
# 1. データの準備 (アヤメデータセットの最初の2つの特徴量と最初の2つのクラスを使用)
iris = datasets.load_iris()
X = iris.data[:100, :2] # Sepal length, Sepal width のみ
y = iris.target[:100] # Setosa (0), Versicolor (1) のみ
# データを標準化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 2. SVMモデルの作成と学習
# ソフトマージンSVM (線形カーネル、C=1.0)
svm_linear = SVC(kernel=’linear’, C=1.0, random_state=42)
svm_linear.fit(X_train, y_train)
# ソフトマージンSVM (RBFカーネル、C=1.0, gamma=’auto’)
svm_rbf = SVC(kernel=’rbf’, C=1.0, gamma=’auto’, random_state=42)
svm_rbf.fit(X_train, y_train)
# 3. 結果の可視化 (決定境界を描画)
plt.figure(figsize=(12, 5))
# 線形カーネルの場合
plt.subplot(1, 2, 1)
DecisionBoundaryDisplay.from_estimator(
svm_linear,
X,
response_method=”predict”,
cmap=plt.cm.coolwarm,
alpha=0.8,
xlabel=iris.feature_names,
ylabel=iris.feature_names,
)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, s=20, edgecolors=”k”)
plt.title(‘SVM with Linear Kernel (C=1.0)’)
# サポートベクターをプロット
plt.scatter(svm_linear.support_vectors_[:, 0], svm_linear.support_vectors_[:, 1],
s=100, facecolors=’none’, edgecolors=’k’, marker=’o’)
# RBFカーネルの場合
plt.subplot(1, 2, 2)
DecisionBoundaryDisplay.from_estimator(
svm_rbf,
X,
response_method=”predict”,
cmap=plt.cm.coolwarm,
alpha=0.8,
xlabel=iris.feature_names,
ylabel=iris.feature_names,
)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, s=20, edgecolors=”k”)
plt.title(‘SVM with RBF Kernel (C=1.0)’)
# サポートベクターをプロット
plt.scatter(svm_rbf.support_vectors_[:, 0], svm_rbf.support_vectors_[:, 1],
s=100, facecolors=’none’, edgecolors=’k’, marker=’o’)
plt.tight_layout()
plt.show()
# テストデータでの精度評価
print(f”Linear Kernel Accuracy: {svm_linear.score(X_test, y_test):.4f}”)
print(f”RBF Kernel Accuracy: {svm_rbf.score(X_test, y_test):.4f}”)
このコードを実行すると、線形カーネル(直線で分離)とRBFカーネル(曲線で分離)の決定境界、そしてサポートベクター(黒い丸で囲まれた点)が可視化されます。SVCクラスの kernel や C といったパラメータを変えることで、様々なSVMモデルを試すことができます。このように、ライブラリを使えば比較的簡単にSVMを実装し、その効果を試すことができます。
まとめ:マージン最大化を理解する重要性
今回は、SVMの中核概念であるマージン最大化について詳しく見てきました。ポイントをまとめると、
- SVMはデータを分類するための決定境界を見つけるアルゴリズム。
- マージン最大化は、決定境界と最も近いデータ点(サポートベクター)との距離(マージン)を最大化することで、汎化性能を高めることを目指す考え方。
- ハードマージンは誤分類を許さないが、線形分離可能なデータや外れ値がない場合に限定される。
- ソフトマージンはスラック変数 ξi とパラメータ C を用いて、ある程度の誤分類やマージン違反を許容し、より現実的なデータに対応する。
- カーネルトリックは、データを高次元空間に写像する(という考え方を使う)ことで、線形分離不可能なデータも扱えるようにする強力なテクニック。カーネル関数 K(xi,xj) が鍵。
マージン最大化は、単にSVMという一つのアルゴリズムの原理であるだけでなく、「どのようにして頑健で信頼性の高い予測モデルを作るか」という機械学習全体の重要なテーマにつながる考え方です。この概念をしっかりと理解しておくことは、AIや機械学習の他の分野を学ぶ上でもきっと役立つはずです。
この記事が、あなたのSVMとマージン最大化への理解を深める一助となれば幸いです!
G検定対策:ここを押さえよう!
G検定の受験を考えている方のために、マージン最大化に関して特に押さえておきたいポイントをまとめました。
- マージン最大化の目的: SVMが目指すのは、マージン(決定境界とサポートベクター間の距離)を最大化すること。その主な目的は汎化性能の向上である点を理解しておく。
- サポートベクター: 決定境界の決定に直接関与する、境界に最も近いデータ点のこと。その役割を理解する。
- ハードマージンとソフトマージン:
- ハードマージン:線形分離可能なデータ用、誤分類を許さない。
- ソフトマージン:線形分離不可能なデータやノイズに対応、スラック変数 ξi とパラメータ C を導入。
- パラメータ C の役割:大きいと誤分類ペナルティ大(ハードマージン寄り)、小さいと誤分類許容度大(マージン重視)。このトレードオフの関係を理解する。
- カーネルトリック:
- 目的:線形分離不可能なデータを高次元空間に写像して線形分離可能にするため。
- 計算:実際に写像せず、カーネル関数 K(xi,xj) を用いて高次元空間での内積を計算する。
- 代表的なカーネル:線形カーネル、多項式カーネル、RBFカーネル(ガウシアンカーネル)の名前と、非線形分離に使われることを覚えておく。
これらのポイントを中心に、SVMの基本的な仕組みを図や具体例と関連付けて理解しておくと、G検定の問題にも対応しやすくなるでしょう。
コメント