
「ネットショッピングでおすすめされた商品、つい見ちゃうことありませんか?」 「動画サイトで次に見るものが自動で出てきて便利ですよね?」
私たちの周りには、まるで心を読まれたかのように「あなたへのおすすめ」を提案してくれるサービスがたくさんあります。これがレコメンデーションシステムです。
実はこの便利な機能の裏側では、AI(人工知能)、特に「教師なし学習」という技術が大活躍しているんです!
この記事を読めば、
- レコメンデーションの基本的な仕組み
- 代表的なレコメンデーションの種類と特徴
- AI(教師なし学習)がどう関係しているのか?
- G検定対策にも役立つ重要ポイント
が、初心者の方にも分かりやすく理解できます。さっそく、レコメンデーションの世界を覗いてみましょう!
まずは基本!レコメンデーションって何だろう?
あなたにピッタリを届ける仕組み
レコメンデーションシステムとは、簡単に言うと「おすすめ機能」のことです。ECサイト、動画配信サービス、音楽アプリ、ニュースサイトなど、あらゆる場所で使われています。
このシステムの目的は、主に以下の3つです。
- ユーザー体験の向上 あなたが興味を持ちそうな情報や商品をすぐに見つけられるようにサポートし、「探しやすさ」「使いやすさ」を高めます。(例:欲しいものがすぐ見つかる!)
- 新たな発見の提供 あなたがまだ知らないけれど、きっと気に入るであろう新しい商品やコンテンツとの出会いを作ります。(例:知らなかった素敵な曲に出会えた!)
- 事業者側のメリット ユーザーがおすすめをきっかけに商品を購入したり、サービスを長く利用したりすることで、売上アップや顧客満足度の向上につなげます。(例:お店の売上が上がる!)
なぜ「教師なし学習」が活躍するの?
ここでAIの登場です。レコメンデーションで特に重要な役割を果たすのが「教師なし学習」というAIの学習方法です。
教師なし学習とは、AIに「これが正解だよ」というお手本(教師データ)を与えずに、データそのものの中から、AIが自力でパターンやルール、仲間分け(クラスタリング)などを見つけ出す技術です。
では、なぜレコメンデーションで教師なし学習が重要なのでしょうか?
それは、レコメンデーションシステムが扱うデータが、主にユーザーの膨大な行動履歴だからです。
- 「誰が」「いつ」「何を見たか」
- 「何を買ったか」「何を高く評価したか」
- 「どんなキーワードで検索したか」
これらのデータには、「このユーザーにはこれを推薦するのが正解!」という明確な答えはありません。
そこで教師なし学習の出番です。AIは、この大量の行動データの中から、
- 「AさんとBさんは、似たような映画をたくさん見ているな…好みが似ているグループかもしれない」
- 「この商品を買った人は、よく一緒にあの商品も買っているな…関連性が高いのかもしれない」
といった、データに隠されたユーザーの好みや商品同士の関係性を自動的に発見してくれるのです。まさに、データの中から「おすすめ」のヒントを探し出す探偵のような役割ですね!
レコメンデーションの代表的な作り方を見てみよう!
レコメンデーションを実現する方法はいくつかありますが、ここでは代表的な3つの手法をご紹介します。
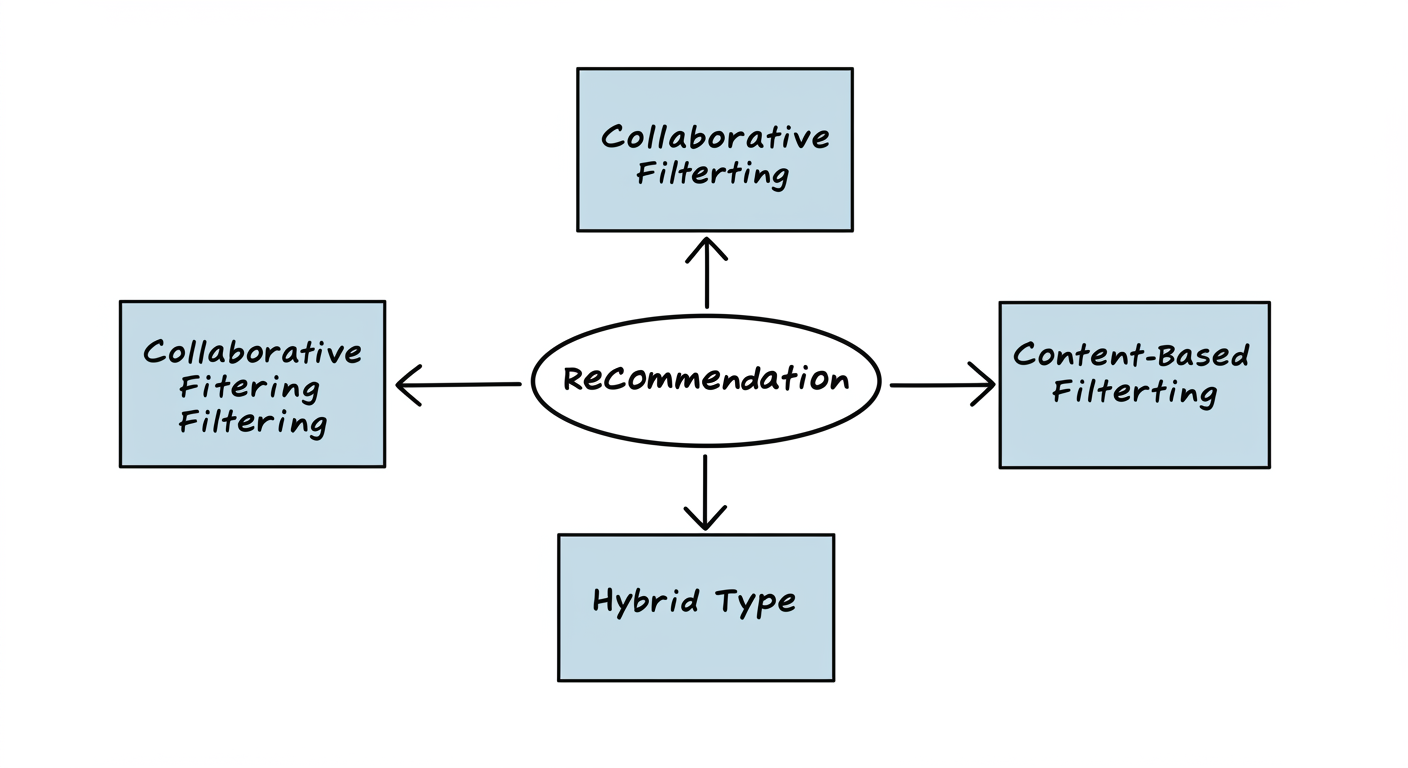
みんなの行動からおすすめ!「協調フィルタリング」
これは、たくさんのユーザーの行動履歴データを使って、「あなたと似た人が良いと言っているもの」や「この商品と一緒に買われているもの」をおすすめする、最もポピュラーな手法の一つです。「みんなの意見を参考にする」イメージですね。
教師なし学習が活きる典型例で、アイテム自体の詳しい情報がなくても、ユーザーの行動パターンからおすすめを作り出せます。
協調フィルタリングには、主に2つのアプローチがあります。
- ユーザーベース協調フィルタリング
- 考え方 「あなたと好みが似ているユーザー」を見つけ出し、その人が高く評価したアイテムをあなたにもおすすめする。
- メリット 自分では見つけられなかったような、意外なアイテムに出会える可能性がある(セレンディピティ)。
- デメリット ユーザー数が増えると計算が大変になる。登録したばかりの新規ユーザー(行動履歴が少ない)にはおすすめしにくい(コールドスタート問題)。
- アイテムベース協調フィルタリング
- 考え方 あなたが過去に高く評価したアイテムと「一緒に購入・閲覧されやすいアイテム」を見つけ出し、それをおすすめする。「この商品を買った人はこんな商品も買っています」でお馴染み。

- メリット ユーザー数が多くても、比較的安定して計算できる。ECサイト(例:Amazon)で広く使われている。
- デメリット 似たようなアイテムばかりおすすめされがち。発売されたばかりの新しいアイテム(他のアイテムとの関連データがない)はおすすめしにくい(コールドスタート問題)。
アイテムの特徴からおすすめ!「コンテンツベースフィルタリング」
こちらは、アイテム(商品、映画、記事など)が持つ特徴(コンテンツ) に注目する手法です。「あなたが過去に好きだったものと似た特徴を持つもの」をおすすめします。
- 考え方 あなたが過去に「SF映画」をよく見ていたとしたら、その映画の「ジャンル:SF」「出演者:〇〇」「監督:△△」といった特徴をAIが分析。そして、同じように「ジャンル:SF」の特徴を持つ、別の映画をおすすめするイメージです。

- メリット
- 他のユーザーの行動履歴がなくても、アイテムの特徴さえわかればおすすめできる。そのため、新しいアイテムにも対応しやすい(コールドスタート問題に強い)。
- なぜそのアイテムがおすすめされたのか、理由が分かりやすい(例:「あなたが好きなSFジャンルの新作です」)。
- デメリット
- アイテムの特徴をうまくデータ化(例:キーワード抽出、タグ付け)する必要がある。
- ユーザーが過去に興味を示したジャンルや特徴のものばかりが推薦されやすく、推薦の幅が狭くなりがち(フィルターバブル問題につながる可能性)。
いいとこ取りで精度アップ!「ハイブリッド型」
名前の通り、協調フィルタリングとコンテンツベースフィルタリングを組み合わせた手法です。
- 考え方 それぞれの手法には得意なことと苦手なことがあります。例えば、協調フィルタリングは意外な発見があるけれどコールドスタートに弱い、コンテンツベースはコールドスタートに強いけれど推薦が偏りがち、といった具合です。そこで、両方をうまく組み合わせることで、お互いの弱点を補い合い、より精度が高く、多様性のあるおすすめを目指します。

- メリット 協調フィルタリングとコンテンツベースフィルタリングの長所を活かし、短所を補うことで、全体的な推薦の質を高められる。
- デメリット システムの設計や実装が複雑になる場合がある。
- 多くのサービス(例:Netflix)では、このハイブリッド型のアプローチが採用されています。組み合わせ方にも、「両方の結果を混ぜる」「片方をメインに、もう片方で補う」など、様々なバリエーションがあります。
もっと詳しく!こんな技術も使われている
レコメンデーションの世界は奥が深く、上記以外にも様々な技術が活用されています。
文書の内容からおすすめ!「トピックモデル(LDAなど)」
これは、たくさんの文書データ(ニュース記事、商品のレビュー、メールなど)の中から、その文書がどんな「話題(トピック)」について書かれているかを自動で見つけ出す技術です。これも教師なし学習の一種です。
- 活用例(ニュースアプリ)
- AI(トピックモデル)が、たくさんのニュース記事を読み込み、「スポーツ」「経済」「テクノロジー」「エンタメ」といった隠れたトピックを抽出します。
- あなたが普段よく読んでいる記事のトピック(例:「テクノロジー」関連が多い)を分析します。
- あなたにおすすめのニュースとして、「テクノロジー」トピックの新しい記事を優先的に表示します。
このように、文書の内容を理解することで、よりユーザーの興味に合った情報を提供できるようになります。
最新トレンド!「ディープラーニング」の活用
最近注目されているのが、AIの中でも特に複雑なパターン認識が得意な「ディープラーニング(深層学習)」をレコメンデーションに応用する動きです。
- 概要 ディープラーニングを使うことで、ユーザーの行動履歴、アイテムの特徴、ユーザーの属性情報(年齢、性別など)、さらにはレビューのテキストや画像といった、様々な種類の情報を組み合わせて、より高度で複雑なユーザーの好みやアイテム間の関係性を学習できるようになりました。
- メリット 従来のモデルでは捉えきれなかったような、よりパーソナルで精度の高いレコメンデーションが期待されています。
- 注意点 高度な分、大量のデータと計算パワーが必要だったり、なぜその推薦になったのか理由の説明が難しくなったりする側面もあります。
(G検定対策としては、「ディープラーニングがレコメンデーションにも応用され始めている」というトレンドを知っておく程度でOKです!)
身近なサービスの「おすすめ」の裏側を探る!
では、私たちが普段使っているサービスでは、どのようにレコメンデーションが活用されているのでしょうか?
Amazon:「これを買った人はこれも買っています」の秘密
- 主に使われている技術 アイテムベース協調フィルタリング
- 仕組み Amazonが持つ膨大な購買データを分析し、「商品Aと商品Bが一緒に買われることが多い」という関連性を発見。あなたが商品Aを見ると、「これを買った人は~」として商品Bをおすすめします。非常に強力で、Amazonの売上に大きく貢献していると言われています。
Netflix:あなただけの映画館を作り出す技術
- 主に使われている技術 ハイブリッド型(協調フィルタリング + コンテンツベース + α)
- 仕組み あなたの視聴履歴(どんな作品を最後まで見たか、高く評価したかなど)だけでなく、作品のジャンル、出演者、あらすじのキーワード、他のユーザーの評価など、様々な情報を組み合わせています。さらに、おすすめ作品の「並び順」や「サムネイル画像」までもユーザーごとに最適化し、クリック率を高める工夫がされています。まさに、あなた専用の映画館を作り上げているのです。
Spotify:「Discover Weekly」はなぜ好みに合うのか?
- 主に使われている技術 複雑なハイブリッド型(協調フィルタリング + コンテンツベース + 自然言語処理)
- 仕組み Spotifyのレコメンデーションは非常に高度です。
- 協調フィルタリング あなたと似た音楽の好みを持つ他のユーザーが聴いている曲をおすすめ。
- コンテンツベース あなたがよく聴く曲の音楽的な特徴(テンポ、音響特性など)を分析し、似た特徴を持つ曲をおすすめ。
- 自然言語処理 インターネット上のブログやニュース記事などから、アーティストや楽曲に関する言及を分析し、トレンドや関連性を把握しておすすめに活用。 これらを組み合わせることで、毎週あなたにパーソナライズされたプレイリスト「Discover Weekly」などが届けられ、新たな音楽との出会いを生み出しています。
ニュースアプリ:関心に合わせた情報収集をサポート
- 主に使われている技術 ハイブリッド型(コンテンツベース + トピックモデル + 協調フィルタリングなど)
- 仕組み あなたがどの記事を読んだか、どのカテゴリ(政治、経済、スポーツなど)に興味があるか(コンテンツベース、トピックモデル)を分析します。さらに、他のユーザーがどんな記事を読んでいるか(協調フィルタリング)といった情報も加味して、リアルタイムであなたに合ったニュースを表示します。忙しい中でも効率的に関心のある情報を得られるようサポートしています。
レコメンデーションが抱える課題と乗り越え方
便利なレコメンデーションシステムですが、いくつかの課題も抱えています。
始めたばかりだと難しい?「コールドスタート問題」
- 課題 サービスを使い始めたばかりの新規ユーザー(どんな好みかデータがない)や、プラットフォームに追加されたばかりの新しい商品・コンテンツ(他のユーザーからの評価や行動履歴がない)に対して、適切なレコメンデーションを行うのが難しいという問題です。
- 対策
- とりあえず人気のあるアイテムや定番アイテムを表示する(人気ランキング)。
- アイテムの特徴を使うコンテンツベースフィルタリングを活用する。
- 会員登録時に好きなジャンルなどをユーザーに尋ねる。
同じようなものばかり?「フィルターバブル問題」
- 課題 レコメンデーションによって自分の好みに合った情報ばかりが表示されるようになると、視野が狭くなり、異なる意見や多様な情報に触れる機会が失われてしまう可能性があります。泡(バブル)の中に閉じ込められたような状態になることから、こう呼ばれます。
- 対策
- アルゴリズムの設計において、効率性だけでなく、推薦の多様性(違うジャンルも混ぜる)や意外性(セレンディピティ)も考慮する。
- ユーザー自身も、意識的に普段見ないジャンルの情報を探してみる。
データが増えると大変?「スケーラビリティ問題」
- 課題 ユーザー数やアイテム数が膨大になると、レコメンデーションの計算に必要な時間やコストが非常に大きくなってしまう問題です。リアルタイムでおすすめを出すのが難しくなることも。
- 対策
- より効率的な計算アルゴリズムを使う(例:モデルベース協調フィルタリング)。
- ユーザーをいくつかのグループに分けて(クラスタリング)、グループごとにおすすめを計算する。
- 処理を複数のコンピューターに分散させる技術(分散処理)を利用する。
まとめ:レコメンデーションと教師なし学習のこれから
今回は、身近な「おすすめ」機能であるレコメンデーションシステムについて、その仕組みや種類、そしてAI(特に教師なし学習)との深い関係を見てきました。
- レコメンデーションは、教師なし学習によって、ユーザーの行動履歴などの膨大なデータから「隠れた好み」や「アイテム間の関連性」を見つけ出し、私たちに最適なおすすめを届けてくれます。
- 代表的な手法として、みんなの行動を参考にする協調フィルタリング、アイテムの特徴を分析するコンテンツベースフィルタリング、両者を組み合わせたハイブリッド型があります。
- Amazon、Netflix、Spotify、ニュースアプリなど、多くのサービスでこれらの技術が活用され、私たちのデジタルライフをより便利で豊かなものにしています。
- 一方で、コールドスタートやフィルターバブルといった課題もあり、より良いレコメンデーションを目指して、技術は常に進化を続けています。ディープラーニングなどの新しい技術も活用され始めています。
レコメンデーションは、AI、特に教師なし学習の力を示す非常に分かりやすい応用例です。次に「おすすめ」が表示されたときは、「裏ではAIが頑張ってくれているんだな」と思いながら見てみると、少し面白いかもしれませんね。
G検定に向けて
G検定の試験対策としては、この記事で解説した以下の点をしっかり理解しておくことが重要です。
- レコメンデーションの基本的な目的と仕組み
- 教師なし学習がレコメンデーションでどのように使われているか(データからパターンや関連性を見つける)
- 協調フィルタリング(ユーザーベース/アイテムベース)とコンテンツベースフィルタリングの原理、メリット・デメリットの違い
- ハイブリッド型の考え方
- コールドスタート問題、フィルターバブル問題とは何か、その概要
特に、協調フィルタリングとコンテンツベースフィルタリングの違いや、コールドスタート問題は頻出のキーワードですので、それぞれの特徴を自分の言葉で説明できるようにしておきましょう!
コメント