
「たくさんの商品データ、アンケート結果…なんだか複雑でよく分からない!」 「G検定の勉強中だけど、多次元尺度構成法(MDS)って難しそう…」
そんな悩みをお持ちではありませんか?
こんにちは!この記事では、データ分析の強力な武器であり、G検定でも頻出の「多次元尺度構成法(MDS Multi-dimensional Scaling)」について、データ分析初心者の方やG検定受験者の方にも分かりやすく、図解を交えながら徹底解説します!
この記事を読めば、あなたはこうなれます!
- MDSが「何をするための技術なのか」をスッキリ理解できる!
- MDSの代表的な活用例(ポジショニングマップなど)がイメージできる!
- G検定で頻出の「PCAとの違い」を明確に説明できるようになる!
- G検定のMDS対策で、どこを押さえるべきかが分かる!
さあ、一緒にMDSの世界を探検して、データ分析力とG検定合格への道を切り開きましょう!
多次元尺度構成法(MDS)って何?一言でいうと「関係性の地図を作る」技術
MDSの基本的な考え方:モノの「関係性」を見える化する
多次元尺度構成法(MDS)とは、たくさんのデータ(例えば、たくさんの商品やブランド、アンケート回答者など)の間にある「距離」や「似ている度合い(類似性)」の関係性を保ったまま、より低い次元の空間(ふつうは2次元や3次元のグラフ)に配置しなおすテクニックです。
ちょっと難しいですね。もっと簡単に言うと、モノとモノの関係性を分かりやすい「地図」に描き出すようなイメージです。
例えば、
- あなたの友人関係を「仲の良さ」に基づいてマップにすると、仲良しグループは近くに、あまり交流がない人は遠くに配置されますよね。
- 日本の主要都市を、実際の距離感になるべく近くなるように紙(2次元)の上に配置するのも、MDSの考え方に近いです。
MDSは、このように複雑に絡み合った高次元のデータ(たくさんの特徴を持つデータ)の関係性を、私たちがパッと見て理解できる2次元や3次元の「地図」に落とし込むことで、「見える化」してくれるのです。
なぜMDSが重要なのか?データに隠された「意味」を発見
では、なぜこのMDSが注目されているのでしょうか?
- 複雑なデータ構造を直感的に理解できる たくさんの数値データだけを見ていても、全体像やデータ同士の関係性はなかなか掴みにくいものです。MDSで視覚化することで、「どの商品とどの商品が似ているのか」「市場全体の中で自社はどの位置にいるのか」といったことが一目で分かります。
- マーケティングで超役立つ 特にマーケティング分野では、MDSが大活躍します。顧客が商品やブランドをどのように認識しているか(ポジショニング)を探ったり、競合と比較して自社の強み・弱みを見つけたり、新しい商品のアイデア(市場の隙間)を発見したりするのに非常に有効です。
- G検定でも問われる重要知識 MDSは、教師なし学習の代表的な次元削減手法の一つとして、G検定でもその概念や他の手法との違いが問われます。しっかり理解しておくことが合格への近道です!
MDSはどうやって「地図」を作るの?基本的な仕組み
MDSがデータ間の関係性を「地図」に描き出すプロセスを、もう少し詳しく見ていきましょう。
入力は「距離」や「似ている度合い」:距離行列とは?
MDSの分析を始めるには、まずデータ同士が「どれくらい似ているか(似ていないか)」あるいは「どれくらい離れているか」を示す情報が必要です。これを距離行列(または非類似度行列)という形で用意します。
これは、N個のデータがあった場合、N行N列の表形式になっていて、各マスにはデータiとデータjの間の「距離」や「非類似度(似ていない度合い)」が数値で入っています。
ポイント
- この「距離」は、物理的な距離だけではありません。
- アンケートで「商品Aと商品Bはどれくらい似ていますか?」と聞いて数値化したものや、購買履歴データから計算した顧客間の行動パターンの類似度なども使えます。
- つまり、データ間の関係性を表す数値であれば、MDSのインプットにできるのです。
目的は「距離感の再現」:低次元空間への配置
距離行列ができたら、MDSはその情報を元に、元のデータの距離関係(近いものは近く、遠いものは遠く)を、できるだけ忠実に再現するように、各データを2次元や3次元の空間(地図の上)に配置していきます。
コンピューターが、配置された点と点の間の距離と、元の距離行列の値を比較しながら、最もズレが少なくなる(=元の関係性をよく再現できている)配置を探してくれる、というイメージです。
2つのアプローチ:計量MDSと非計量MDS【G検定ポイント】
MDSには、入力するデータの性質によって、主に2つの種類があります。この違いはG検定でも問われやすいので、しっかり押さえましょう!
- 計量MDS (Metric MDS)
- 使うデータ 距離や類似度が「具体的な数値」で測られているデータ(比例尺度)。例えば、「A地点とB地点の距離は10km」「商品Aの売上は商品Bの2倍」など、数値そのものに意味があるデータです。
- 目的 低次元空間での点と点の間の「実際の距離」が、元のデータの距離(の比率)とできるだけ一致するように配置します。
- 非計量MDS (Non-metric MDS)
- 使うデータ 距離や類似度が「順序」でしか分からないデータ(順序尺度)。例えば、「商品Aは商品Bよりも好き」「ブランドXはブランドYよりも高級なイメージがある」など、大小関係や順位は分かるけれど、その差が具体的にどれくらいかは分からないデータです。アンケートの評価などでよく使われます。
- 目的 低次元空間での点と点の間の距離の「大小関係(順序)」が、元のデータの順序とできるだけ一致するように配置します。
- ストレス値 非計量MDSでは、元の順序と再現された距離の順序がどれだけ一致しているかを「ストレス (Stress) 値」という指標で評価します。ストレス値が小さいほど、元の関係性をうまく再現できている(=当てはまりが良い)と判断されます。
G検定対策メモ 計量MDSは「量」を、非計量MDSは「順序」を重視すると覚えましょう!
MDSのすごい活用例!マーケティングから製品開発まで
MDSが実際にどのように役立てられているのか、具体的な活用例を見てみましょう。特にマーケティング分野での応用が豊富です。
市場の「見える化」:ポジショニングマップ
これはMDSの最も代表的な活用例です。競合する商品やブランドが、顧客からどのようなイメージで見られているか(=どのようにポジショニングされているか)を、2次元のマップ上に可視化します。
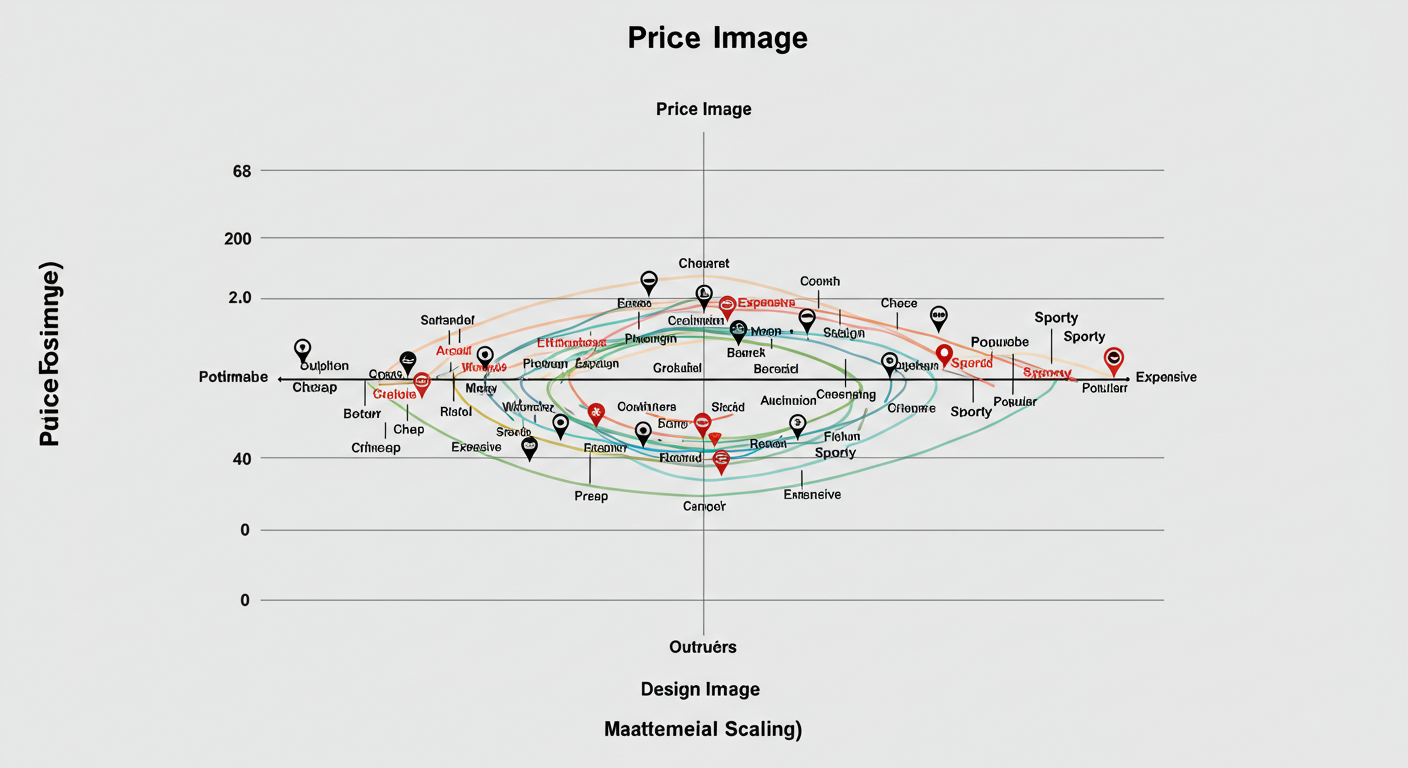
- A社は「手頃な価格で大衆的」、B社は「高価格でスポーティ」と認識されていることが分かります。
- C社とD社は比較的近い位置にあり、顧客からは似たようなブランドと認識されている(=競合関係が強い)可能性があります。
- 右下の「手頃な価格でスポーティ」な領域には、あまりブランドが存在しないように見えます。これは、もしかしたら新しい市場のチャンス(ブルーオーシャン)かもしれません。
このようにポジショニングマップを使うことで、
- 自社ブランドの現在の立ち位置の確認
- 競合ブランドとの関係性の把握
- ターゲット顧客の設定
- 新しい市場機会の発見
などに役立ちます。
顧客の「本音」を探る:知覚マップ
ポジショニングマップの中でも、特に顧客の「頭の中にあるイメージ」や「評価軸」に基づいて作成されたものを知覚マップ (Perceptual Map) と呼ぶことがあります。アンケートで様々な形容詞(例:高級感がある、使いやすい、革新的など)で商品を評価してもらい、その結果をMDSで分析することで、顧客がどのような軸で商品を認識しているのかを探ることができます。
新商品開発のヒントに:プロダクトマップ
既存の商品ラインナップや競合商品を、その「物理的な特性」(例:サイズ、重さ、機能数など)に基づいてMDSでマッピングしたものをプロダクトマップ (Product Map) と言います。これにより、
- 自社製品ラインナップの中での各製品の位置づけの確認
- 売れ筋商品とそうでない商品の特性の違いの分析
- まだ市場に存在しない特性の組み合わせ(=新商品のアイデア)の発見
などに繋がります。
MDSと他の手法の違いは?【G検定最重要ポイント】
MDSは教師なし学習の次元削減手法ですが、他にも似たような目的を持つ手法があります。特に主成分分析 (PCA) との違いは、G検定で頻繁に問われる最重要ポイントです。k-means法との違いも理解しておきましょう。
MDS vs 主成分分析 (PCA)
| 特徴 | 多次元尺度構成法 (MDS) | 主成分分析 (PCA) |
| 主な目的 | データ点間の距離や類似度を保持して低次元化・可視化 | データの分散(ばらつき)を最大化する軸を見つけて低次元化・要約 |
| 入力データ | データ点間の距離行列または類似度行列 | データ点の特徴量(元のデータそのもの) |
| 焦点 | 距離・類似度の保持 | 分散の最大化 |
| 捉える関係 | 非線形な関係も捉えやすい | 主に線形な関係 |
| 軸の意味 | 解釈が難しい場合がある | 元の特徴量の線形結合で、比較的解釈しやすい |
| 計算量 | データ数が多いと大きくなる傾向 | 比較的少ない |
| 使い分け例 | ポジショニングマップ作成、関係性の可視化 | データの特徴抽出、ノイズ除去、他の分析の前処理 |
G検定対策メモ
- 目的の違いが最重要! MDSは「距離を保つ」、PCAは「分散を最大にする」。
- 入力データの違いもポイント! MDSは「距離行列」、PCAは「元のデータ」。
- 「ポジショニングマップならMDS!」 と覚えておくと良いでしょう。
MDS vs k-means法
| 特徴 | 多次元尺度構成法 (MDS) | k-means法 |
| 主な目的 | データ点間の距離を保持して次元削減・可視化 | データをk個のクラスタ(グループ)に分割する |
| カテゴリ | 次元削減 | クラスタリング |
| 出力 | 低次元空間での各データ点の座標 | 各データ点のクラスタラベルとクラスタ中心 |
MDSとk-meansは目的が全く異なります。MDSはデータを分かりやすく「配置」するのに対し、k-meansはデータを「グループ分け」します。ただし、MDSで可視化した結果を見て、どのようなグループがありそうか考え、k-meansで実際に分けてみる、といった組み合わせで使うこともあります。
MDSを使う上でのメリット・デメリット【注意点も解説】
MDSは強力なツールですが、万能ではありません。メリットとデメリット(注意点)を理解しておくことが大切です。
メリット:直感的理解、潜在構造の発見、質的データもOK
- 直感的に分かりやすい 結果が地図のようなグラフで示されるため、複雑なデータ間の関係性を一目で把握できます。プレゼンにも効果的!
- 隠れた構造が見える アンケート回答者が意識していないような、潜在的な評価軸やグループ構造を発見できることがあります。
- 質的なデータも扱える 非計量MDSを使えば、「好き嫌い」や「イメージ評価」のような順序データも分析できます。
- 市場での立ち位置が明確に 競合と比較した自社のポジショニングを客観的に把握し、戦略立案に役立ちます。
- 非線形な関係も捉えられる PCAなどの線形手法では捉えきれない、複雑な関係性も可視化できる場合があります。
デメリット:軸の解釈、次元数の決定、計算量【注意点】
- 軸の意味付けが難しい 得られたマップの縦軸・横軸が具体的に「何を意味するのか」は、自動的には分かりません。分析者がデータの内容や背景知識に基づいて解釈する必要があります(恣意的になる可能性も)。
- 最適な次元数が分かりにくい 何次元のマップにするのが最適か(通常は2次元か3次元)、客観的な基準はありません。非計量MDSのストレス値などを参考にしますが、低すぎると情報不足、高すぎると解釈困難になります。
- データの偏りに影響される アンケート調査の場合、回答者の選び方によって結果が歪む可能性があります。
- 計算コスト データ数が非常に多くなると、計算に時間がかかることがあります。
- 結果の安定性 アルゴリズムや初期値によっては、実行するたびに少し異なる結果になる可能性があります。
注意点まとめ
- MDSの結果(特に軸の意味)は鵜呑みにせず、他の情報と合わせて慎重に解釈しましょう。
- 目的に合ったデータ(類似度/非類似度)を用意することが重要です。
- 計量/非計量の選択を間違えないようにしましょう。
G検定対策まとめ:MDSはここを押さえよう!
最後に、G検定合格に向けてMDSの重要ポイントを総まとめします!
最低限覚えるべき必須キーワード
以下のキーワードは、意味をしっかり説明できるようにしておきましょう。
- 多次元尺度構成法 (MDS)
- 次元削減
- 類似性 / 非類似性
- 距離行列
- ポジショニングマップ / 知覚マップ / プロダクトマップ
- 計量MDS (Metric MDS)
- 非計量MDS (Non-metric MDS)
- ストレス値 (Stress Value)
G検定で問われるポイント【再確認】
G検定では、特に以下の点が問われやすい傾向にあります。
- MDSの定義と目的
- 「データ間の距離や類似度の関係を保持したまま、低次元空間に配置する手法」であることを理解する。
- 主な目的が「データの可視化による構造理解」であることを押さえる。
- 過去問例:「多次元空間における距離の関係が崩れないように低次元空間において再現する手法である。」→これが正解の選択肢。
- 計量MDSと非計量MDSの違い
- 計量MDS → 量的データ(比例尺度)、距離の絶対値(比率)を再現。
- 非計量MDS → 順序データ(順位尺度)、距離の大小関係(順序)を再現。ストレス値で評価。
- PCAとの違い
- 最重要比較ポイント!
- 目的 MDS (距離保持) vs PCA (分散最大化)
- 入力 MDS (距離行列) vs PCA (元データ)
- 焦点 MDS (類似性) vs PCA (相関・共分散)
- 活用例
- マーケティングにおけるポジショニングマップが代表例であることを知っておく。
おすすめ学習法&参考資料
- 公式テキスト/参考書 G検定の公式テキストや推奨参考書(例:松尾豊先生監修「人工知能基礎」など)で、MDSとPCAの箇所をしっかり読み込みましょう。
- 問題演習 対策問題集や過去問で、MDSの定義、種類、PCAとの違いを問う問題を重点的に解きましょう。選択肢の間違い探し形式に慣れておくことが大切です。
- この記事を活用 この記事で紹介した図解(ポジショニングマップ)や比較表(特にPCAとの違い)を頭に入れておくと、理解が深まり、記憶に定着しやすくなります。
- 東京大学 松尾豊先生監修「人工知能基礎」
- G検定公式テキスト 第2版
まとめ:MDSを理解して、データ分析力とG検定合格を掴もう!
今回は、多次元尺度構成法(MDS)について、その基本的な考え方から仕組み、活用例、そしてG検定対策まで、初心者の方にも分かりやすく解説しました。
MDSのポイントをおさらい
- データ間の「関係性(距離・類似度)」を保ったまま「見える化(地図化)」する技術。
- マーケティングのポジショニング分析などで大活躍。
- G検定ではPCAとの違いが超重要!
MDSは、複雑なデータの中に隠されたパターンや構造を、私たち人間が直感的に理解できる形にしてくれる強力なツールです。G検定対策としてだけでなく、今後データ分析に関わる上で必ず役立つ知識となるでしょう。
この記事が、あなたのMDSへの理解を深め、G検定合格への一助となれば幸いです。ぜひ、さらに学習を進めて、データ活用のスキルを磨いていってくださいね!応援しています!
コメント