
どうもにこいちです。Webサービスを運営する皆さん、2025年11月18日の夜、本当に肝を冷やしましたよね。
突然、X(旧Twitter)やChatGPTといった巨大サービスが一斉にダウン。「まさか自社サービスに何かあったのか?」と冷や汗をかいた情報システム担当者の方も多いはずです。原因は、インターネットの根幹を支えるCloudflare(クラウドフレア)のグローバルネットワーク障害でした。
今回の障害は、私たちWebサービス運営者に非常に重大な教訓を突きつけました。それは、「世界最高峰のインフラでも、単一障害点になり得る」という冷徹な事実です。
この記事では、単なるニュースの解説で終わらせません。今回の障害を教訓とし、あなたのビジネスの継続性を守るために、情報システム担当者が今すぐ実践すべき具体的で現実的な「冗長化・多重化対策3選」を徹底的に解説します。
結論から申し上げると。
あなたのサービスを大規模なダウンから守る唯一の方法は、「CDNの多重化」と「DNSレベルでの自動切り替え」の導入です。
この記事を読めば、次に同様の障害が発生しても慌てずに対処できる、自社サービスを守るための具体的な行動指針が手に入ります。ぜひ最後まで読み込み、すぐに実行に移してください。
なぜ世界中が停止したのか?2025年11月Cloudflare大規模障害の全貌
今回のCloudflare障害の深刻さは、「利用しているサービスが広範すぎる」という点にあります。この事実を冷静に分析し、その教訓をビジネスに活かすことが、情報システム担当者としての責務です。
発生日時と影響範囲(X/ChatGPTなど)
今回の障害は、日本時間で2025年11月18日午後8時48分頃に発生しました。週末の夜という、ユーザーの活動が活発な時間帯を直撃したため、影響は甚大でした。
- 影響の深刻度: Cloudflareを利用する世界中のWebサイト、オンラインサービス、そして企業向けのAPI接続の一部に、断続的な接続エラーや動作不良が報告されました。
- 代表的な影響サービス:
- X(旧Twitter):タイムラインの読み込みエラーや投稿の失敗が多発。
- ChatGPT / ClaudeなどのAIサービス:AIモデルへの接続が不可になり、「エラーが発生しました」のメッセージが多数表示されました。
- その他、オンラインゲーム、ECサイト、企業のSaaS連携など、多岐にわたるサービスで「500 Internal Server Error」や「Please unblock challenges.cloudflare.com to proceed.」といったメッセージが表示されました。

今回の事象は、単なるサーバーダウンではなく、インターネットの玄関口とも言えるインフラが機能不全に陥った、非常に重大な事態でした
根本原因は「内部サービスの劣化」と「トラフィック急増」
Cloudflare社の公式発表や報道を総合すると、障害の根本原因は、特定の内部サービスの異常な劣化と、それに伴うグローバルネットワークへの異常なトラフィックの急増だとされています。
簡単に言えば、「心臓となるべきシステムの一部がバグを起こし、それがネットワーク全体に過負荷をかけるパニック状態を引き起こした」という構図です。
復旧には数時間かかりましたが、この事実が示しているのは、「世界トップクラスの冗長性を持つ企業であっても、ソフトウェア的なバグや予期せぬ負荷集中によって、サービスが停止し得る」という、サービスの根幹に関わるリスクです。
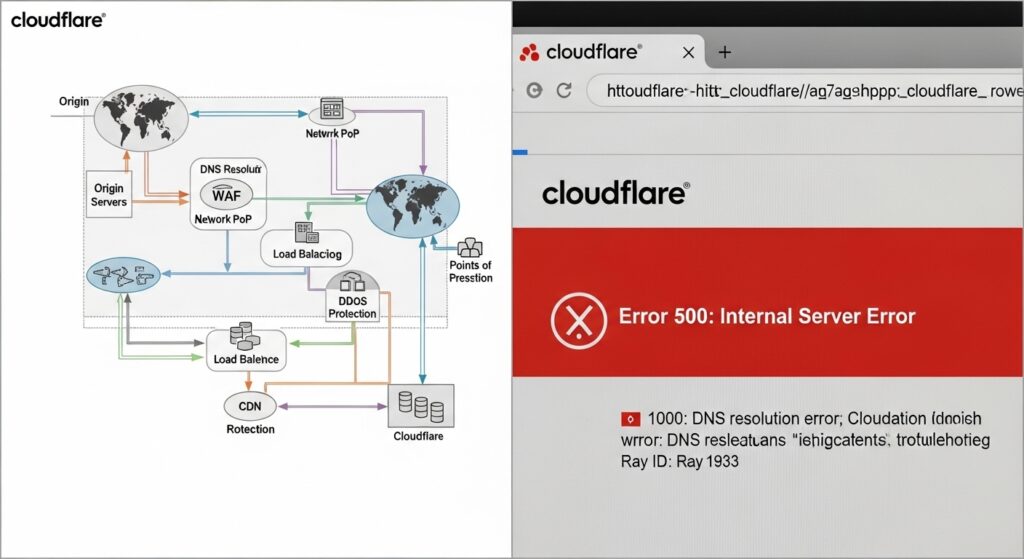
Cloudflare障害が突きつけた「単一障害点」というリスク
今回のCloudflare障害から、情報システム担当者が最も深く心に刻むべき教訓は、「世界最高峰のインフラも、単一障害点(Single Point of Failure: SPOF)になり得る」という現実です。
「一つの障害が世界を止める」インフラ依存の危険性
Cloudflareが停止したことで、なぜあれほど多くのグローバルサービスが停止したのでしょうか?それは、現代のインターネットインフラがCloudflareに極度に依存しているからです。
Cloudflareは、世界100か国以上、200都市以上にデータセンターを持つ広大なネットワークを運営しており、そのネットワークは世界のWebトラフィックのかなりの部分を処理しています。
- 依存のメカニズム: 多くの企業は、パフォーマンス向上、DDoS攻撃防御、Webアプリケーションファイアウォール(WAF)によるセキュリティ強化のためにCloudflareを利用しています。つまり、ユーザーからのアクセスは、必ずCloudflareのネットワークを経由してから、自社のサーバーに到達するという設計になっているのです。
- 危険性: この設計は通常時は強力なメリットとなりますが、Cloudflare側で大規模な内部障害が発生すると、ユーザーのアクセスが会社のサーバーに届く前の「関所」でブロックされてしまいます。どんなに自社サーバー側が健全でも、どうすることもできません。
この「関所」の停止こそが、今回の障害の本質であり、インフラ依存の最大の危険性です
Cloudflareの役割とは?【CDN/WAFの仕組みを簡単解説】
あらためて、Cloudflareがどのような役割を担い、なぜその停止が世界を混乱させるのかを理解しておきましょう。
| サービス名 | 役割 (担当者のベネフィット) | 停止時の影響 |
| CDN (コンテンツデリバリネットワーク) | サーバー負荷軽減、コンテンツ高速化(低遅延) | ページの表示速度が極端に低下、キャッシュミスによりサーバーがダウン。 |
| WAF (Webアプリケーションファイアウォール) | SQLインジェクションなどのWeb攻撃防御 | セキュリティ機能が停止し、自社サーバーが攻撃にさらされるリスク。 |
| DDoS防御 | 大量の不正トラフィック(DDoS)から保護 | ネットワーク飽和により、正規のユーザーアクセスも遮断される。 |
多くのシステム担当者は、これらのセキュリティとパフォーマンスの「万能薬」としてCloudflareに全幅の信頼を置いています。しかし、今回の障害は、その「万能薬」自体が単一の弱点になり得ることを示しました。
【情報システム担当者向け】今すぐ実践すべき「再発防止」と「冗長化対策」3選
単なるニュースで終わらせず、今回の障害を「自社サービスの強靭化」につなげるのが、プロの情報システム担当者です。
ここでは、コストと手間を考慮しつつ、即効性の高い現実的な「備え」を3つご紹介します。
対策1: DNSレベルでのヘルスチェックとフェイルオーバー構成の導入
これが、Cloudflare障害のリスクを最も手軽に、かつ効果的に回避できる最優先の対策です。
- 問題点: Cloudflareがダウンすると、あなたのWebサイトのDNSレコードがCloudflareのネットワークを指している限り、トラフィックはブロックされ続けます。
- 解決策: プライマリのCDN(例: Cloudflare)とは別に、セカンダリのCDN(例: Fastly, Akamai, またはAWS CloudFrontなど)を用意し、その間でトラフィックを自動的に切り替える仕組みを構築します。
- 具体的な実装: Amazon Route 53などの高機能なDNSサービスを活用します。Route 53のヘルスチェック機能を使えば、Cloudflareを経由したエンドポイントの応答を監視し、異常が検知された瞬間に自動的にセカンダリのCDNのエンドポイントへとトラフィックを振り替えることができます。

サービスのダウンは一刻を争います。人間の手による切り替えでは間に合いません。システムが自動で判断し、最短数秒でフェイルオーバーするこの仕組みは、現代のWebサービス運営の必須条件です。
対策2: コストを抑えた複数CDNのスタンバイとWAF多重化
「CDNを二重化するのはコストが高い」という意見は理解できます。しかし、サービス停止による機会損失と信頼失墜のコストは、CDNのコストを遥かに上回ります。
- 戦略的な多重化: 全てのトラフィックを常時二重化する必要はありません。セカンダリのCDNは、トラフィックが少ないリージョン、または緊急時のみに利用する「コールドスタンバイ」として契約すれば、コストを抑えられます。
- WAFの多重化: CloudflareのWAFに依存しすぎるのも危険です。Webサーバーの手前には、AWS WAFやAzure Firewallなどの異なるプロバイダーのWAFを配置し、セキュリティ機能も多重化することで、レイヤーの異なる障害リスクに対応できます。
重要なのは、「いざという時に、すぐに切り替えられる準備ができているか」です。本番環境でテストし、切り替え手順をドキュメント化しておきましょう。
対策3: 障害発生時の緊急オペレーションと顧客へのアナウンス体制の構築
技術的な対策だけでなく、組織的な対応策も企業の信頼性を守る上で不可欠です。
- 緊急連絡網の明確化: 障害発生が確認された際、誰が、どのシステム(ネットワーク、サーバー、アプリ)の責任者かを明確にした緊急連絡網を策定します。夜間・休日の連絡フローは特に重要です。
- 顧客アナウンスの迅速化: Cloudflareのような外部インフラの障害の場合、原因究明に時間がかかることがあります。その際、「詳細調査中」と沈黙するのではなく、「外部ネットワークに起因する接続障害が発生しており、現在、対策を講じています」といった中間報告を、X(旧Twitter)やステータスページで速やかに発信することが、顧客からの信頼を守ります。
障害情報だけでなく、「あなたのビジネスは動いているか?」という情報が、情報システム担当者にとっては最優先事項です。外部障害でも、自社システムの健全性をチェックするプロセスをマニュアルに組み込みましょう。
まとめ:あなたのビジネスを守るための「危機管理マニュアル」を今すぐ作成しよう
今回のCloudflareの大規模障害は、私たちWebサービス運営者にとって、「セキュリティと可用性への投資」の重要性を再認識させる痛烈な教訓となりました。
重要なポイントを改めて振り返ります。
- 障害の本質: 世界的なインフラであるCloudflareも、内部サービス劣化やトラフィック急増により停止し、単一障害点(SPOF)になり得るという現実。
- 対策の結論: 最も現実的で効果的な対策は、プライマリCDNとは別のセカンダリCDNを用意し、DNSレベルでのヘルスチェックと自動フェイルオーバーの仕組みを導入することです。
- 組織的な備え: 技術的な冗長化だけでなく、緊急時の迅速な連絡体制と、顧客への透明性のあるアナウンスの構築が、信頼を守ります。
あなたは今、今回の障害の事実を知っただけでなく、具体的な解決策も手に入れました。次に取るべき行動は一つです。
すぐに社内のインフラチームと相談し、「CDN多重化・冗長化の実現可能性」を検討してください。
まずは低コストで始められる「対策1:DNSレベルでのヘルスチェック」から着手することを強くおすすめします。一歩踏み出すことで、あなたのビジネスは大規模障害のリスクから大きく遠ざかります。
この記事が、あなたの会社の危機管理マニュアル作成の一歩となれば幸いです。
コメント