
「AIって、どうやって物事を理解しているんだろう?」 「G検定で『知識表現』ってよく聞くけど、何が重要?」
G検定の学習を進める中で、こんな疑問を持ったことはありませんか?
AIが人間のように考え、問題を解決するためには、単にデータを処理するだけでなく、そのデータが持つ「意味」や「関係性」を理解する必要があります。そのための重要な技術が**「知識表現」**です。
G検定のシラバス「人工知能をめぐる動向」の中でも、「知識表現」はAIの発展を理解する上で欠かせない、頻出分野の一つです。
この記事では、G検定合格を目指すあなたが「知識表現」を体系的に理解できるよう、以下の流れで徹底解説します!
- 知識表現の始まり: AIブームとエキスパートシステムの登場
- 知識を形にする技術: 意味ネットワークとオントロジー
- 立ちはだかった壁: 知識獲得のボトルネック
- 現代への応用: ワトソンと東ロボくんの挑戦
- 人間とAIの心理: イライザ効果
この記事を読めば、知識表現の歴史から主要な技術、G検定で押さえるべきポイントまで、しっかり理解できます。AIが世界をどう捉えようとしてきたのか、その進化の軌跡を一緒に見ていきましょう!
知識表現の始まり:AIブームとエキスパートシステムの登場
AIの研究は一直線に進んできたわけではなく、期待と停滞を繰り返す「ブーム」と共に発展してきました。知識表現が脚光を浴びたのは、第2次AIブーム(1980年代〜1990年代初頭)のことです。
- 第1次AIブーム(1950年代後半〜1960年代): パズルや簡単なゲームなど、「推論」と「探索」で解ける問題が中心でした。しかし、現実世界の複雑な問題には対応しきれず、ブームは下火に。
- 第2次AIブーム(1980年代〜1990年代初頭): 「知識こそが知能の源泉だ!」という考え方が主流になります。特定の分野に特化した専門家の「知識」をコンピュータに教え込み、問題解決をさせようというエキスパートシステムが開発され、大きな注目を集めました。まさに「知識の時代」の到来です。
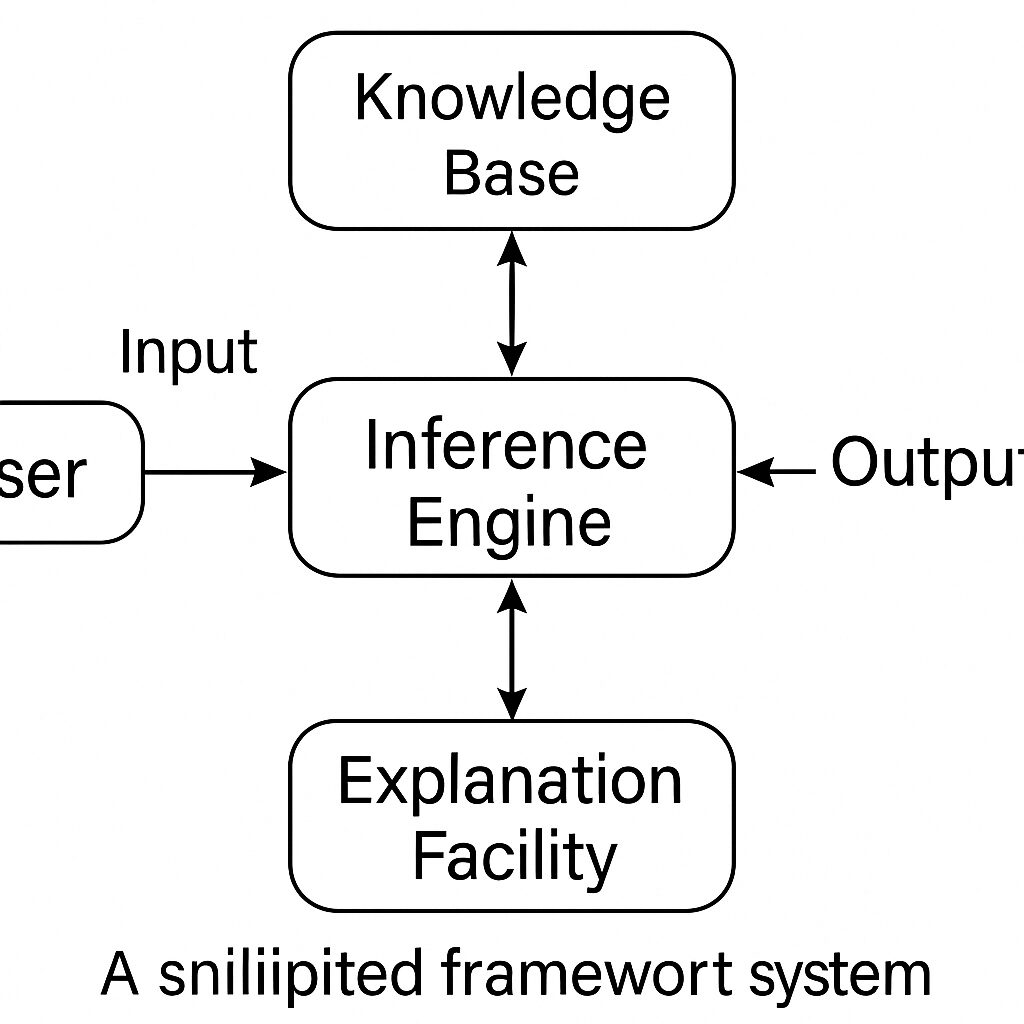
エキスパートシステムとは?
特定の専門分野の知識(ルールや事実)を「知識ベース」として蓄積し、それを使って推論エンジンが専門家のように診断やアドバイスを行うシステムです。
代表的なエキスパートシステム:
- DENDRAL: 有機化合物の構造を推定
- MYCIN: 感染症の診断と治療法をアドバイス
- XCON: コンピュータの構成を自動決定し、DEC社で年間数百万ドルのコスト削減に貢献
これらの成功により、AIの実用化への期待が一気に高まりました。
ちょっと寄り道:人工無脳とイライザ効果
第2次AIブームより少し前、1960年代に登場したELIZA(イライザ)というプログラムも、知識表現の初期の試みとして重要です。ELIZAは、ユーザーの発言に含まれるキーワードに反応し、定型文を返すことで、あたかも人間と対話しているかのように見せかけるチャットボットの元祖でした。
ELIZAは、深い知識や理解を持っていたわけではありません。しかし、多くの人がELIZAに対して「理解されている」「感情があるのでは?」と感じてしまう現象が起こりました。これをイライザ効果と呼びます。
これは、人間がいかに容易にコンピュータに人間性を投影してしまうかを示すと同時に、自然言語処理における知識表現の難しさと可能性を示唆する重要な事例です。
【G検定ポイント】
- 第2次AIブームは「知識の時代」、エキスパートシステムが主役だったことを覚える。
- エキスパートシステムの基本的な仕組み(知識ベース+推論エンジン)と代表例(MYCINなど)を把握する。
- ELIZAとイライザ効果は、初期の自然言語処理と知識表現の試みとして理解する。
知識を形にする技術:意味ネットワークとオントロジー
エキスパートシステムの「知識ベース」に知識を蓄えるためには、人間が持つ知識をコンピュータが理解できる形(形式知)に変換する必要があります。そのための代表的な手法が意味ネットワークとオントロジーです。
意味ネットワーク:概念を繋げて地図を作る
意味ネットワークは、物事の概念(モノ、コト)を「ノード(点)」で、概念間の関係性を「エッジ(線)」で表現する、比較的シンプルな方法です。まるで、概念の関連性を地図のように描き出すイメージです。
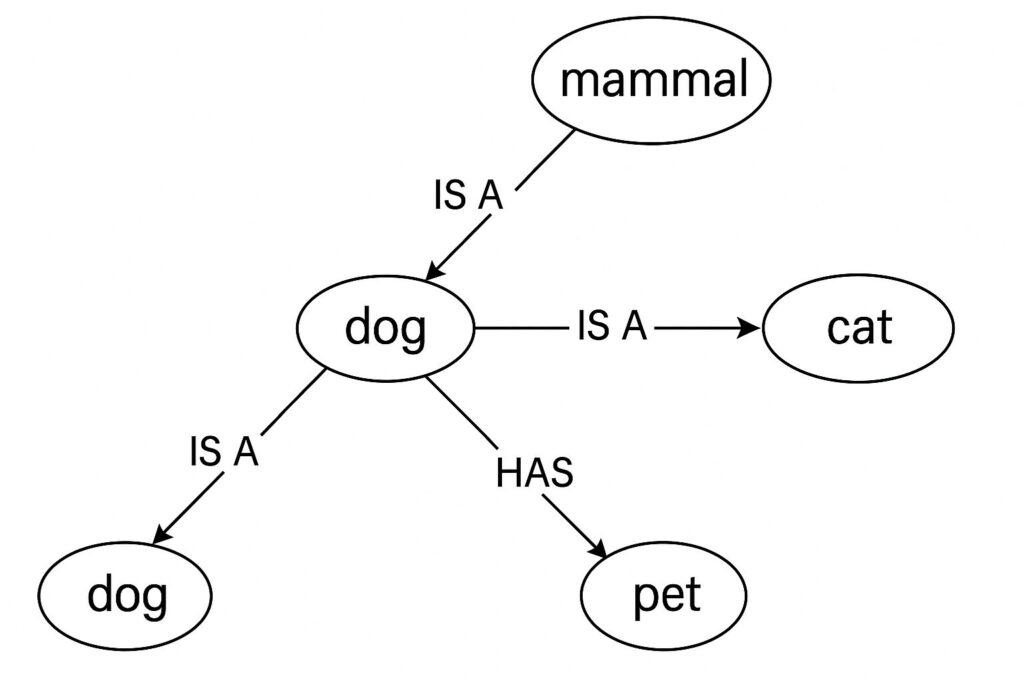
- メリット: 直感的で分かりやすい、知識の関連性を視覚化しやすい。
- デメリット: 大規模になると複雑化する、エッジ(関係性)の定義が曖昧になりやすい、厳密な推論には向かない。
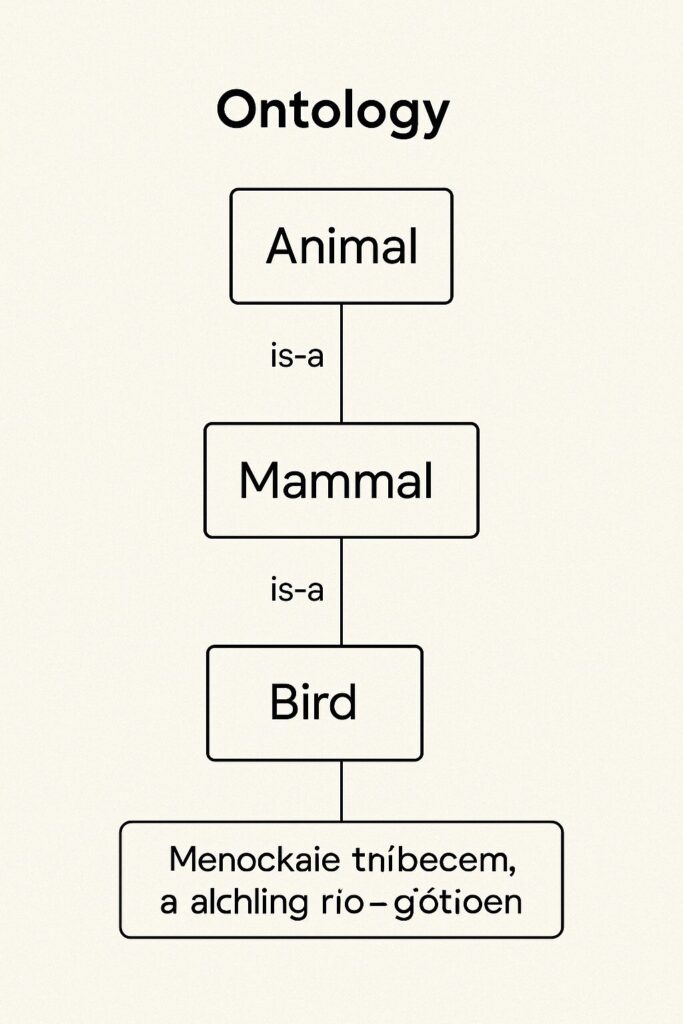
オントロジー:より厳密な知識の辞書・ルールブック
意味ネットワークの曖昧さを克服し、より厳密に知識を定義・体系化するのがオントロジーです。特定の分野(ドメイン)における概念、その属性、概念間の関係性、そして守るべきルール(制約、公理)などを明確に記述します。「コンピュータが使える、厳密な辞書でありルールブック」のようなものです。
オントロジーでは、特に重要な関係性として以下の二つがあります。
- is-a 関係(イズア関係): ある概念が別の概念の種類の一つであることを示す階層関係。「柴犬 is-a 犬」「犬 is-a 動物」のように、下位の概念は上位の概念の性質を受け継ぎます(継承)。
- part-of 関係(パートオブ関係): ある概念が別の概念の部分・構成要素であることを示す関係。「エンジン part-of 車」「タイヤ part-of 車」のように、物事の構造を表現します。この全体と部分の関係性を扱う分野をメレオロジーと呼ぶこともあります。
- メリット: 知識の曖昧さを減らせる、知識の共有・再利用がしやすい、コンピュータによる自動推論が可能になる、異なるシステム間でのデータ連携が容易になる。
- デメリット: 設計・構築に専門知識と手間がかかる。
オントロジーの構築には、OWL (Web Ontology Language) や RDF (Resource Description Framework) といった標準化された言語が使われることが多く、これにより知識の共有や再利用が促進されます。セマンティックWeb(コンピュータがWebページの情報の意味を理解できるようにする構想)などでも重要な技術です。
【G検定ポイント】
- 意味ネットワークとオントロジーの基本的な違い(形式性、厳密さ)を理解する。
- オントロジーにおける**is-a関係(継承)とpart-of関係(構成)**の意味と役割をしっかり覚える。
- オントロジーが知識の共有・再利用や自動推論に役立つことを理解する。
立ちはだかった壁:知識獲得のボトルネック
エキスパートシステムは大きな期待を集めましたが、やがて限界も見えてきました。その最大の要因が**「知識獲得のボトルネック」**です。
これは、専門家が持つ知識をコンピュータが理解できる形(知識ベース)に落とし込むのが、非常に困難で時間とコストがかかるという問題です。
なぜボトルネックが生じるのか?
- 暗黙知の壁: 専門家の知識には、経験や勘に基づく「暗黙知」(言葉にしにくい知識)が多く含まれるため、それをルールなどの「形式知」にするのが難しい。
- 専門家の負担: 専門家自身も、自分がどうやって判断しているかを明確に説明できないことがある。知識を引き出す作業は専門家にとっても大きな負担になる。
- 知識の矛盾・不整合: 多くの知識を集めると、矛盾が生じたり、一貫性を保つのが難しくなったりする。
- 維持・更新の困難: 新しい知識が登場したり状況が変化したりした際に、知識ベースを更新し続けるのが大変。
このボトルネックにより、エキスパートシステムの開発は高コスト化し、適用範囲も限定的なものになりがちでした。また、ルールベースのシステムは、予期せぬ状況への対応や、人間のような常識的な判断、柔軟な思考が苦手という課題もありました。
これらの限界が、第2次AIブームが終焉を迎える一因となったのです。
【G検定ポイント】
- 知識獲得のボトルネックが何を指すのか(専門家の知識を形式知化する困難さ)を理解する。
- ボトルネックが生じる理由(暗黙知、専門家の負担、矛盾、維持コスト)を押さえる。
- これがエキスパートシステムの限界となり、第2次AIブーム終焉の一因となったことを理解する。
現代に息づく知識表現:応用事例
第2次AIブームは終焉しましたが、知識表現の研究が止まったわけではありません。その技術や考え方は、形を変えながら現代のAIにも活かされています。ここでは代表的な事例として、IBMの「ワトソン」と日本の「東ロボくん」を紹介します。
IBM Watson:クイズ王を倒した知識活用システム
IBMのワトソンは、2011年にアメリカの人気クイズ番組「Jeopardy!」で人間のチャンピオンに勝利し、世界を驚かせました。ワトソンは、単なる検索エンジンではありません。
- 膨大な知識源: 百科事典、辞書、ニュース記事、文学作品に加え、DBpedia(Wikipediaの構造化データ)やWordNet(英単語の意味ネットワーク)、Yago(大規模オントロジー)といった知識ベースも活用。
- 高度な自然言語処理: 質問の意図を深く理解する。
- 仮説生成と検証: 膨大な知識から複数の解答仮説を生成し、それぞれの根拠を評価して最も確からしい答えを導き出す。
ワトソンは、まさに知識表現技術(特にオントロジーや知識グラフの活用)と自然言語処理、機械学習を高度に融合させたシステムと言えます。現在では、医療(診断支援)、金融(リスク分析)、コールセンターなど、様々な分野で応用されています。
東ロボくん:AIは東大に入れるか?
日本の国立情報学研究所が中心となって進めた「ロボットは東大に入れるか(東ロボくん)」プロジェクトは、AIが人間と同じように大学入試問題を解けるか、という挑戦でした。
- 多様な科目に挑戦: 数学、物理、世界史、英語など、様々な科目の問題を解くAIを開発。
- 一定の成果: 数学の自動解答や、世界史の正誤判定問題で高い正答率を達成。多くの私立大学で合格可能性80%以上を示す成績を収めた。
- 見えた限界: 一方で、文章の意味を深く理解する必要がある読解力や、常識を必要とする問題には苦戦。AIが人間のように「意味を理解する」ことの難しさが改めて浮き彫りになりました。
東ロボくんは、目標としていた東大合格には至りませんでしたが、AIの現在の能力と限界を示す貴重な知見をもたらしました。ここでも、問題文の理解や解答生成のために、自然言語処理や知識ベースといった知識表現関連技術が活用されました。
【G検定ポイント】
- ワトソンがクイズ番組で勝利したこと、膨大な知識源と高度な自然言語処理、仮説生成・検証能力を持つことを理解する。医療などへの応用も知っておく。
- 東ロボくんプロジェクトの目的(AIによる大学入試挑戦)、成果(数学、世界史など)、そして限界(読解力、意味理解の困難さ)を把握する。
まとめ:知識表現から学ぶ、AIの知性の本質
今回は、G検定の重要テーマである「知識表現」について、その歴史、主要技術、課題、そして現代への応用までを解説してきました。
- 第2次AIブームでは、エキスパートシステムが中心となり、「知識」の重要性が認識された。
- 知識をコンピュータに表現する技術として、意味ネットワークや、より厳密なオントロジー(is-a/part-of関係が重要)が登場した。
- しかし、知識獲得のボトルネックという大きな壁に直面した。
- ワトソンや東ロボくんは、知識表現技術を活用した現代的なAIの挑戦事例である。
- 初期のELIZAとイライザ効果は、人間とAIの関係性を考える上で示唆に富む。
知識表現は、AIが単なる計算機から、より知的な存在へと進化するための根幹をなす技術です。現代のAI、特にディープラーニングはデータから自動で特徴量を学習しますが、その背後にある「世界をどうモデル化し、理解するか」という問いは、知識表現が追求してきたテーマと深く繋がっています。
G検定の学習を通して知識表現を理解することは、AI技術の表面的な知識だけでなく、その発展の歴史と本質を掴む上で非常に重要です。
この記事が、あなたのG検定合格、そしてAIへの理解を深める一助となれば幸いです。頑張ってください!
コメント