
「G検定の勉強を始めたけど、強化学習ってなんだか難しそう…」 「Q関数?状態価値関数?言葉は聞くけど、違いがよくわからない…」
そんな風に感じていませんか? 強化学習はG検定の重要分野ですが、専門用語が多くて戸惑ってしまう方も少なくありません。
でも、大丈夫! この記事では、強化学習の中でも特に超重要な「行動価値関数(Q関数)」について、予備知識ゼロの初心者の方でも理解できるよう、イチから丁寧に解説します。
この記事を読めば、以下のことがスッキリわかります!
- 強化学習って、コンピューターがどうやって「賢く」なるの?
- 「Q関数」って、一体何者? 何が便利なの?
- よく似てる「状態価値関数」との決定的な違い
- 迷路の例で、Q関数がどうやってゴールへの近道を見つけるかがわかる!
- G検定でQ関数についてどんなことが問われるか
G検定合格はもちろん、AIの基本的な考え方を理解する上でも役立つ知識です。肩の力を抜いて、一緒に学んでいきましょう!
まずは基本から!強化学習ってどんな仕組み?
Q関数を理解するために、まずは「強化学習」の基本的な考え方をおさえましょう。難しく考えなくてOKです!
強化学習とは? 一言でいうと、コンピューター(エージェント)が、試行錯誤しながら「ご褒美(報酬)」をたくさんもらえるような行動を学習する仕組みです。まるで、ペットがおやつをもらうために「お手」を覚えるのに似ていますね。
登場人物をおさえよう!
- エージェント: 学習して行動する主人公(例:迷路の中を動くロボット)
- 環境: エージェントが動き回る世界(例:迷路そのもの)
- 状態 (s): エージェントがいる場所や状況(例:迷路のどのマスにいるか)
- 行動 (a): エージェントが取れる動き(例:上下左右に移動する)
- 報酬 (r): 行動の結果としてもらえるご褒美やペナルティ(例:ゴールに着いたら+100点、壁にぶつかったら-10点)
- 方策 (π): 「どの状態で、どの行動をとるか」というエージェントの行動ルール
エージェントは、今の「状態」を見て、「方策」に従って「行動」します。その結果、環境から「報酬」をもらい、次の「状態」に移ります。このサイクルを繰り返して、最終的にもらえる報酬の合計が最大になるような「最高の行動ルール(最適方策)」を見つけ出すのが、強化学習の目標です。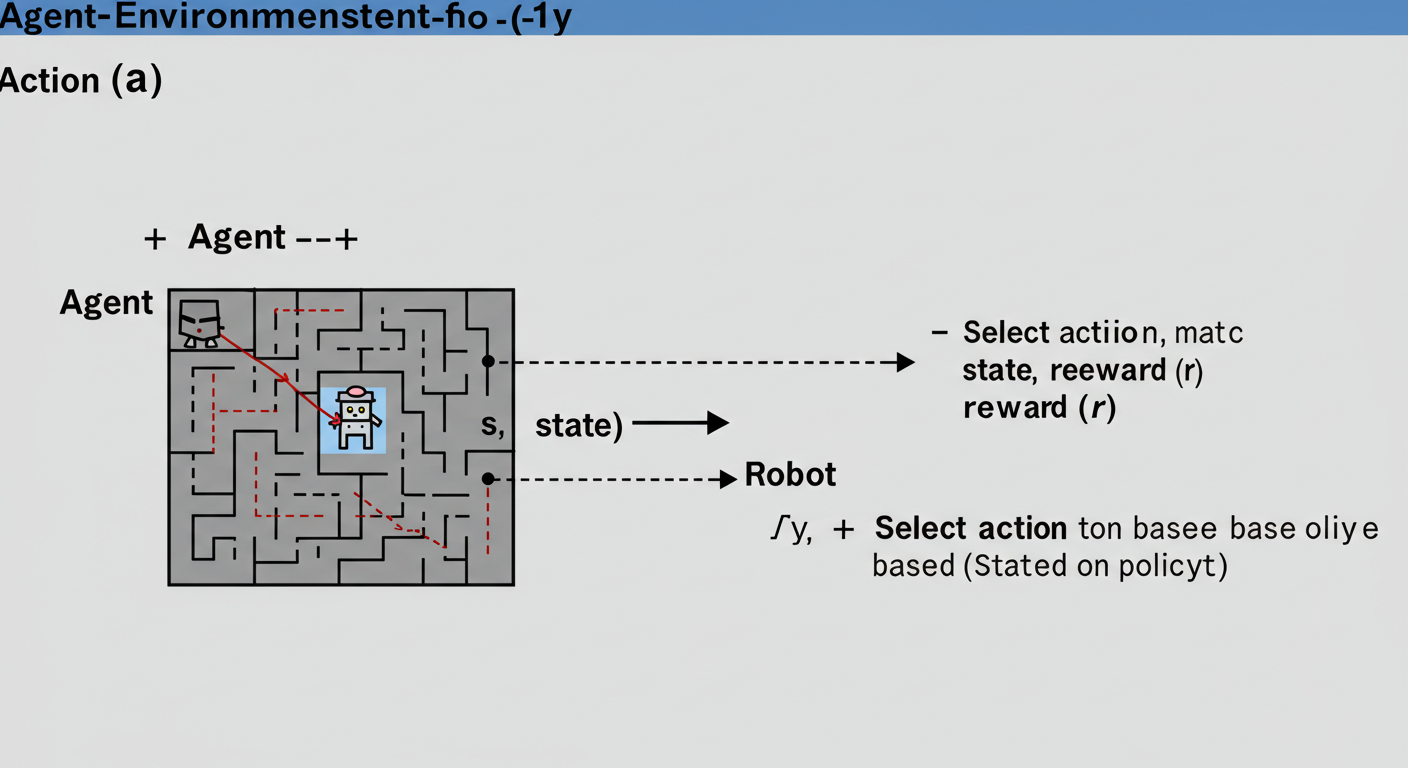
「状態の良さ」を測る:状態価値関数 V(s)
さて、エージェントが賢い行動ルールを見つけるためには、「どの状態が良い状態で、どの状態が悪い状態か」を判断する基準が必要です。そこで登場するのが価値関数です。
まずは基本の「状態価値関数 V(s)」から見ていきましょう。
状態価値関数 V(s) とは? その状態にいると、将来的にどれくらいの報酬が期待できるか(=その状態の良さ) を表す値です。
迷路の例で考えてみましょう。
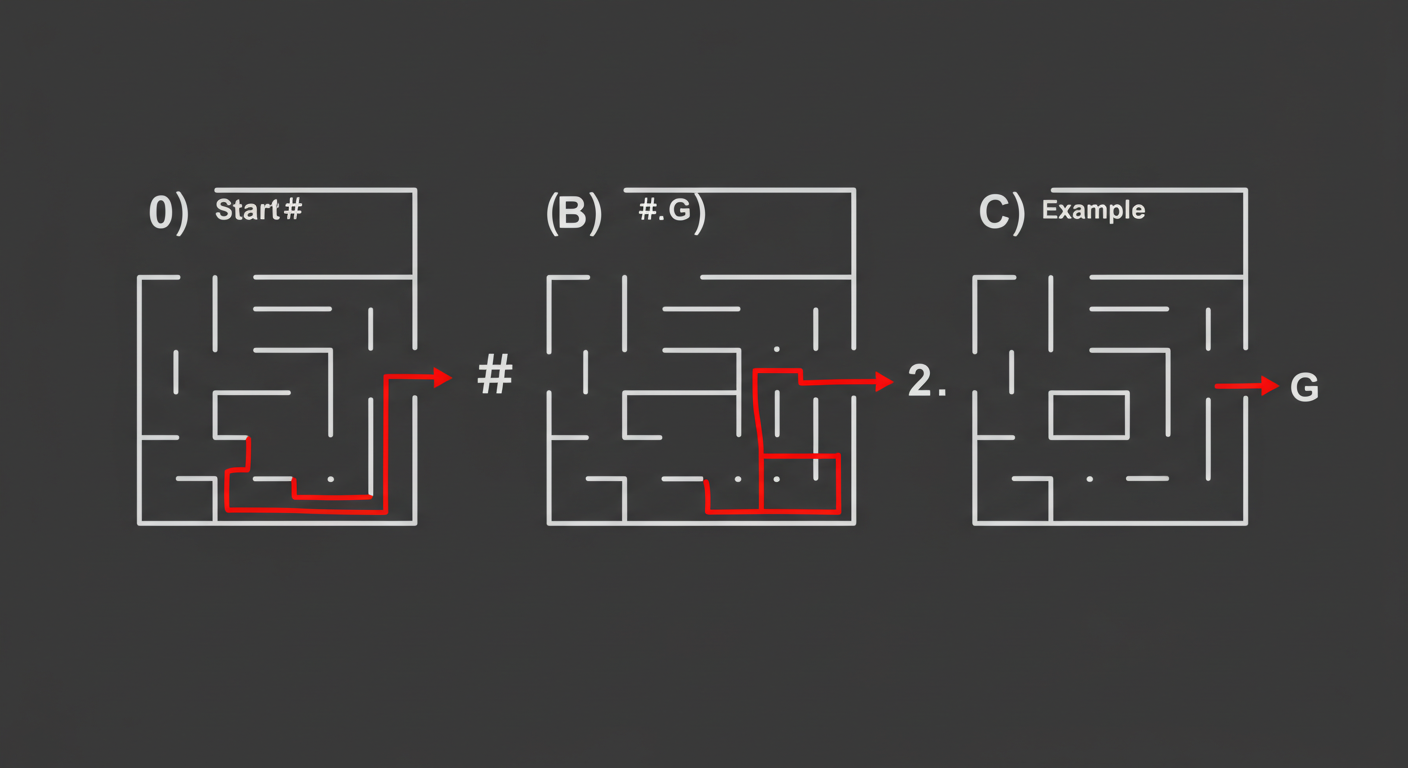
- ゴール(B2)にいる状態は、最高のご褒美がもらえるので価値がとても高いです。
- ゴール(B2)のすぐ隣のマス(B1やC2)は、あと一歩でゴールなので、価値は比較的高くなります。
- スタート(A0)地点は、ゴールから遠いので価値は低めです。
- 壁(#)の中の状態は価値が非常に低い(あるいは定義されない)でしょう。
このように、状態価値関数 V(s) は、そのマス(状態)自体がどれくらい「良い場所」かを示します。V(A0)、V(B1) のように、各マス(状態)に対して一つの値が決まります。
本日の主役!「行動の良さ」を測る:行動価値関数 Q(s, a)
いよいよ本日の主役、「行動価値関数 Q(s,a)」の登場です! 状態価値関数 V(s) とは何が違うのでしょうか?
行動価値関数 Q(s,a) とは? ある状態 s で、特定の行動 a を取った場合に、将来的にどれくらいの報酬が期待できるか(=その状態でその行動をとることの良さ) を表す値です。
ここが超重要ポイント! V(s) は「状態(マス)の良さ」でしたが、Q(s,a) は「状態(マス)で、特定の行動(移動)をすることの良さ」を表します。
迷路の例で見てみましょう。マス(B1)にいるとします。
(0) (1) (2)
(A) S . #
(B) . [B1] G
(C) # . .
エージェントはマス(B1)から、上(A1)、下(C1)、右(B2=ゴール)に進むことができます(左は通路なので進めると仮定)。それぞれの行動に対してQ値が決まります。
- Q(B1,右): マス(B1)で右(ゴール方向)に進む行動の価値。ゴールに直行できるので、非常に高い値になります。
- Q(B1,上): マス(B1)で上に進む行動の価値。ゴールから遠ざかるので、値は低くなります。
- Q(B1,下): マス(B1)で下に進む行動の価値。ゴールに近づくので、(B1, 上)よりは高い値になるでしょう。
- Q(B1,左): マス(B1)で左に進む行動の価値。ゴールから遠ざかるので、値は低くなります。
このように、Q(s,a) は「どのマス」で「どっちに進む」のが良いかを具体的に教えてくれるのです。
まとめ:V(s)とQ(s, a)の違い
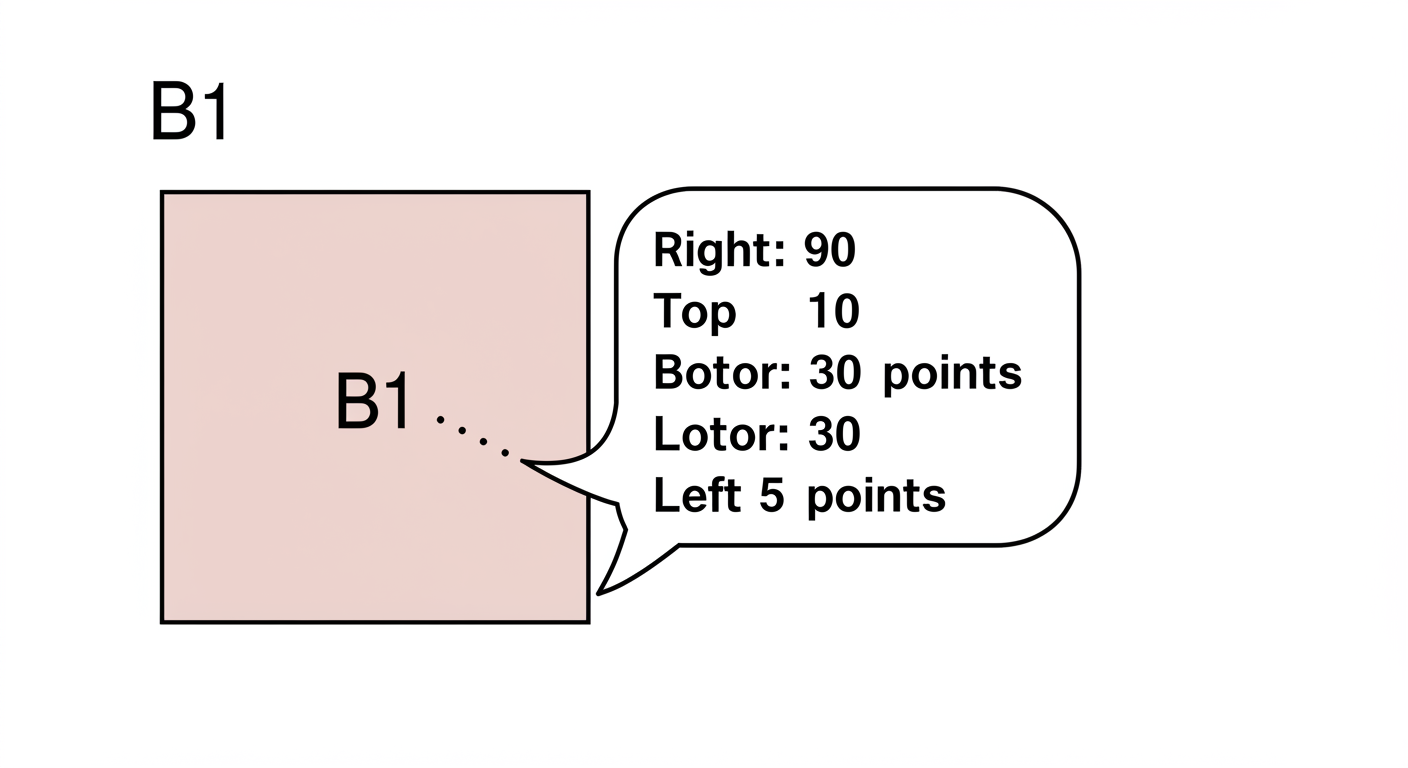
| 関数 | 評価するもの | 具体例 (迷路) |
| 状態価値関数 V(s) | 状態 s そのものの良さ | マス(B1)の良さ = 60点 |
| 行動価値関数 Q(s,a) | 状態 s で行動 a を取ることの良さ | マス(B1)で右に進む良さ = 90点 |
なぜQ関数が便利なの? V(s) だけだと、「マス(B1)はまあまあ良い場所だな」としか分かりません。でも Q(s,a) が分かれば、「マス(B1)にいるなら、右に進むのが一番良さそうだ!」と、具体的な次の行動を決めることができます。これがQ関数が強化学習で非常に重要な理由です!
ちょっとだけ数式:Q関数の気持ち
G検定では数式も問われる可能性があるので、少しだけ見てみましょう。怖くないですよ!
Qπ(s,a)=∑s′Pss′a[Rss′a+γVπ(s′)]
これは、「状態 s で行動 a をした時の価値 Qπ(s,a) は、行動 a の結果、次の状態 s′ になった時の『すぐもらえる報酬 Rss′a』と『その先の状態 s′ の価値 Vπ(s′)(をちょっと割り引いたもの γVπ(s′))』を足したものの期待値(平均みたいなもの)だよ」という意味です。
- γ (ガンマ): 割引率 (0~1の値)。将来もらえる報酬をどれくらい割り引くか。1に近いほど未来を重視、0に近いほど目先の報酬を重視します。「明日の100円より今日の90円」みたいな感覚ですね。
今は数式を完璧に覚えなくてもOK。「Q値は、すぐもらえる報酬と、その先の状態の価値を足し合わせたものなんだな」くらいの理解で大丈夫です。
Q関数はどうやって求める? Q学習の仕組み
エージェントは、どうやってこの便利な Q(s,a) の値を知るのでしょうか? 自分で学習しないといけませんよね。その代表的な学習方法が「Q学習」です。
Q学習のステップ
Q学習では、エージェントは実際に迷路の中を動き回りながら、試行錯誤を通じてQ値を更新していきます。
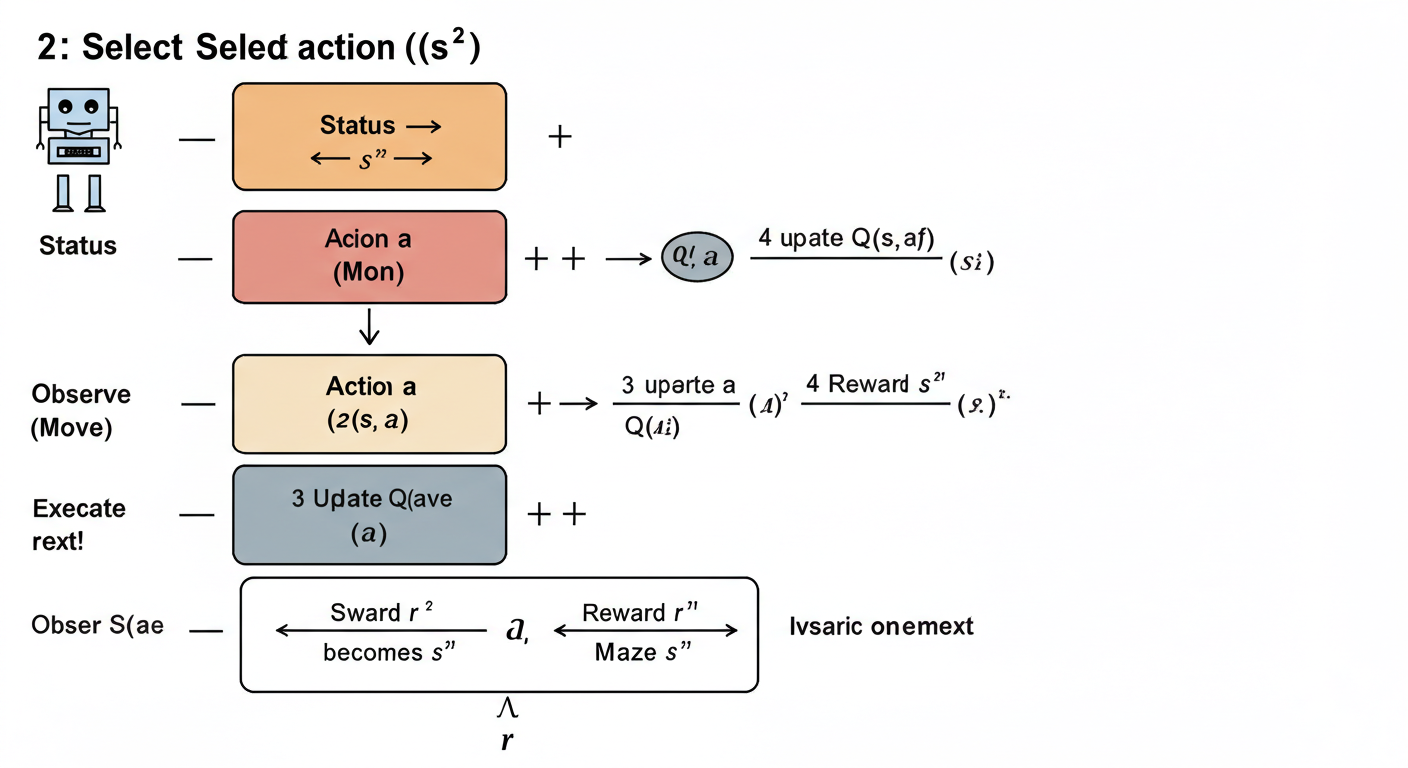
+———+ ②行動aを選択 +———+
| 状態s | —————> | 行動a |
| (ロボット)| <————— | (移動) |
| を観測 | ④Q(s,a)を更新 | |
+———+ +———+
↑ | ③行動aを実行
| ⑤状態がs’になる |
| ↓
+———+ ③報酬rと次の +———+
| 環境 | <————— | 状態s’ |
| (迷路) | 状態s’を観測 | |
+———+ +———+
- Qテーブルを準備: まず、「状態(マス)」と「行動(移動方向)」の全ての組み合わせに対するQ値を記録する表(Qテーブル)を作ります。最初は全部0点とか、適当な値を入れておきます。
| 上へ | 下へ | 左へ | 右へ |
——-|——|——|——|——|
マス A0 | 0 | 0 | 0 | 0 |
マス A1 | 0 | 0 | 0 | 0 |
マス B0 | 0 | 0 | 0 | 0 |
マス B1 | 0 | 0 | 0 | 0 |
… | … | … | … | … |
- 行動を選ぶ: 今いるマス(状態 s)で、Qテーブルを見て、どの方向(行動 a)に進むか決めます。(どうやって決めるかは後述)
- 行動して、結果を見る: 選んだ方向に実際に進んでみて、報酬 r (例: ゴールなら+100点)と、移動先の新しいマス(次の状態 s′)を確認します。
- Q値を更新!: ここがキモ! 実際にやってみて分かった情報 (r と s′) を使って、さっき選んだ行動 a のQ値 Q(s,a) を更新します。 更新の考え方(ざっくりイメージ): 「今回やった行動 a の価値は、思ったより良かった(悪かった)から、Qテーブルの点数を少し上げよう(下げよう)」 具体的には、ベルマン方程式という考え方に基づいた更新式を使います。 Q(s,a)←Q(s,a)+α[(r+γmaxa′Q(s′,a′))−Q(s,a)] (読み方:古いQ値 + 学習率 × ( 実際に得られた価値[っぽいもの] – 古いQ値 )) α (アルファ)は学習率で、どれくらい点数を更新するかを表します。maxa′Q(s′,a′) は、移動先のマス s′ で一番高いQ値(一番良さそうな行動の価値)です。
- 繰り返し: エージェントは新しいマス s′ に移動し、またステップ2から繰り返します。
これを何度も何度も、エージェントが迷路の中をグルグルと探検することで、Qテーブルの値がどんどん正確になっていき、最終的には各マスでどっちに進むのが一番良いかが分かるようになるのです!
賢く学習するための工夫:ε-greedy(イプシロングリーディ)法
Q学習で行動を選ぶとき、ただQ値が一番高い行動ばかり選んでいると、もしかしたらもっと良いルートがあるのに見逃してしまうかもしれません。かといって、適当に行動しすぎても学習が進みません。
そこで使われるのが「ε-greedy(イプシロングリーディ)法」という作戦です。
- 普段(確率 1−ϵ)は、活用 (Exploitation): 今のQテーブルを見て、一番点数が高い行動を選ぶ(一番賢そうな手を選ぶ)。
- たまに(確率 ϵ)は、探索 (Exploration): あえてランダムな行動を選ぶ(もしかしたら良い発見があるかも?と寄り道してみる)。
ϵ (イプシロン) は小さな値(例えば0.1 = 10%)です。これにより、普段は学習した知識を活用しつつ、たまに新しい可能性を探ることで、より良いルートを見つけられる可能性を高めるのです。G検定でもこの「探索と活用」の考え方は重要です!
G検定に向けて:関連キーワードもチェック!
Q関数・Q学習と合わせて、以下のキーワードもG検定では問われる可能性があります。簡単に押さえておきましょう。
- マルコフ決定過程 (MDP): 強化学習の多くが、この数学的な枠組みに基づいています。「次の状態は今の状態と行動だけで決まる」というマルコフ性が前提です。Q関数もこの枠組みの中で定義されます。
- バンディットアルゴリズム: 「探索と活用」のバランスが重要な、よりシンプルな問題設定。ε-greedy法などが使われる点で共通しています。
- 方策勾配法: Q学習(価値ベース)とは違うアプローチで、「方策(行動ルール)」そのものを直接学習します(方策ベース)。REINFORCEやActor-Criticといった手法がこれにあたります。アプローチの違いを理解しておきましょう。
まとめ:Q関数を理解して、G検定も強化学習も怖くない!
お疲れ様でした!今回は、強化学習の心臓部ともいえる「行動価値関数(Q関数)」について、初心者向けに解説しました。
今日のポイント:
- Q関数 Q(s,a) は「状態で行動すること」の良さを測る!
- V(s)(状態の良さ)との違いをしっかり区別しよう!
- Q関数が分かれば、最適な行動が選べる!
- Q学習は、試行錯誤でQテーブルを更新してQ関数を学ぶアルゴリズム!
- Q学習では「ε-greedy法」で探索と活用をバランスさせるのが大事!
G検定では、これらの定義、違い、仕組みを正確に理解しているかが問われます。特に、V(s) と Q(s,a) の違い、Q学習の更新プロセス、ε-greedy法の意味は頻出です。
今日の迷路の例を思い出せば、「Q関数って、結局どのマスでどっちに進めばゴールに近いか教えてくれる便利な点数表みたいなものだな」とイメージできるはずです。
強化学習は奥が深いですが、基本を押さえれば必ず理解できます。この記事が、あなたのG検定合格と、AI技術への理解を深める一歩となれば、とても嬉しいです!
コメント