
こんにちは!AIやデータサイエンスの世界に足を踏み入れた皆さん、G検定の学習、頑張っていますか?
「強化学習ってなんだか難しそう…」「Q値って聞いたことあるけど、よくわからない…」
そんな風に感じている方も多いかもしれません。でも、大丈夫!
AIがゲームをクリアしたり、ロボットが最適なルートを見つけたりする、そんな賢い動きの裏側には、今回ご紹介する「Q値(きゅーち)」という考え方が深く関わっています。
この記事では、G検定合格を目指す初心者の方に向けて、強化学習の超重要キーワード「Q値」を、世界一わかりやすく解説します!
この記事を読むと、こんなことができるようになります!
- Q値が「何なのか」を具体的にイメージできる!
- Q値がAIの学習で「なぜ重要なのか」がわかる!
- G検定で「どこが問われるか」のポイントが掴める!
難しい数式は最小限に、簡単な迷路の例を使って、一緒に楽しく学んでいきましょう!
Q値ってなに?AIの「行動の価値」を測るモノサシ
まず、Q値とは何か? 一言でいうと、「ある状況(状態)で、ある行動をとったら、将来どれくらい良いことがあるか?」を数値で表したものです。AIがより良い選択をするための「行動の価値」を示すモノサシ、と考えると分かりやすいかもしれません。
イメージで掴む!迷路で考えるQ値
言葉だけだとピンとこないですよね。そこで、簡単な「迷路」を例に考えてみましょう!
【迷路のイメージ図】
+—+—+—+
| S | | W | S: スタート
+—+—+—+
| | W | | G: ゴール
+—+—+—+
| | | G | W: 壁 (通れない)
+—+—+—+
(各マスが「状態」、上下左右への移動が「行動」)
- 状態 (State): あなたが今いる迷路のマス目の位置です。スタート地点、通路の真ん中、ゴール前など、それぞれのマスが異なる「状態」です。
- 行動 (Action): 各マスで取れる動き。「上へ進む」「下へ進む」「右へ進む」「左へ進む」などです。(壁には進めません)
- 報酬 (Reward): 行動した結果、もらえるご褒美(またはペナルティ)。例えば、
- ゴールにたどり着いたら: +10点
- 壁にぶつかったら: -5点
- それ以外のマスに進んだら: -1点(早くゴールしたいので、無駄な動きは少しマイナス)
さて、ここでQ値の登場です! Q値は、「特定のマス(状態)で、特定の方向(行動)へ進んだら、最終的にゴールまでにどれくらいの合計報酬(点数)が期待できるか?」を示します。
例えば、
- ゴール手前のマス(状態)で、ゴール方向へ進む(行動) → 高いQ値が期待できそう! (+10点がすぐそこ!)
- スタート地点(状態)で、壁に向かって進む(行動) → 低いQ値になりそう… (-5点のペナルティ)
- 行き止まりのマス(状態)で、唯一戻れる方向へ進む(行動) → マイナスかもしれないけど、壁にぶつかるよりはマシなQ値かも?
このように、各「状態」と「行動」のペアに対して、「その行動、どれくらい良さそう?」を数値化したものがQ値なのです。
Q値の正式な定義(ちょっとだけ数式)
専門的には、Q値は Qπ(s,a) と書かれたりします。
Qπ(s,a)=Eπ[Rt+1+γRt+2+γ2Rt+3+…∣St=s,At=a]
うーん、いきなり難しそうですね…! でも、分解すれば大丈夫。
- Qπ(s,a): あるルール(π: パイ)に従っているとき、状態 s で行動 a をとるQ値
- Eπ[…]: ルール π に従ったときの期待値(平均的にどれくらいか)
- Rt+1: 次の瞬間にもらえる報酬 (Reward)
- γ: 割引率(ガンマ)。0以上1未満の値で、「未来の報酬をどれだけ重視するか」を示す係数。γが0に近いと目先の報酬重視、1に近いと遠い未来の報酬までしっかり考慮します。
- Rt+1+γRt+2+…: 将来もらえる報酬の合計(ただし、未来の報酬は少し割り引いて考える)
- ∣St=s,At=a: 今の状態が s で、とった行動が a であるという条件
【超訳】 「今の状態 s で行動 a をとったら、将来もらえる報酬(ちょっと未来割引あり)の合計は、平均してどれくらいになるかな?」
【G検定対策】 数式を完璧に覚える必要はありません! 「Q値は、ある状態である行動をとったときの、将来にわたる報酬の期待値である」こと、そして「γ(割引率)は未来の報酬を割り引くための係数である」ことを理解しておけばOKです。
なぜQ値が重要?AIの行動決定の羅針盤
なぜこのQ値がそんなに大事なのでしょうか?
それは、AI(エージェント)が「今、何をすべきか」を決めるための強力な指針になるからです。
もし、すべての「状態」と「行動」のペアに対する「正しいQ値」を知っていたら…?
迷路の例で言えば、AIは各マス(状態)で、一番Q値が高い方向(行動)を選んで進めば、自然と最適なルート(最短でゴールにたどり着くなど)を見つけ出すことができるのです!
Q値は、まさにAIにとっての「進むべき道を示す羅針盤」のような役割を果たします。
Q値とV値はどう違う?「状態」と「状態+行動」の評価
Q値とよく似た言葉に「V値(ぶいち)」または「状態価値関数」というものがあります。これもG検定で問われることがあるので、違いをしっかり理解しておきましょう。
V値とは?その「状態」自体の良さ
V値 (V(s)) は、「その状態 s にいること自体が、将来どれくらい良いことにつながるか?」を示す値です。特定の行動は考慮せず、その状態からスタートした場合に期待される将来の報酬の合計を表します。
迷路の例でいうと、
- ゴールのマスにいる状態 → V値は最高! (もうゴールしてるから)
- ゴールに近いマスにいる状態 → V値は高いはず (ゴールが近いから)
- スタート地点のマスにいる状態 → V値はそれなり? (まだゴールまで遠い)
- 周りを壁に囲まれた行き止まりのマスにいる状態 → V値は低いかも…
このように、V値はその「状態」そのもののポテンシャルや価値を示す指標です。
Q値とV値の使い分け【G検定ポイント】
| 特徴 | Q値 (Q(s,a)) | V値 (V(s)) |
| 評価対象 | 状態 s と行動 a のペア | 状態 s そのもの |
| 意味 | その状態でその行動をしたら良いか? | その状態自体が良いか? |
| 用途 | 具体的な行動選択に使いやすい | 状態の良し悪しの評価に使う |
| 迷路の例 | 「ゴール前でゴールへ進む」のは良い? | 「ゴール前のマス」は良い場所か? |
【G検定ポイント】 Q値は「状態と行動のペア」の価値、V値は「状態」そのものの価値、という違いをしっかり覚えましょう!
また、最適なQ値 (Q∗(s,a)) と最適なV値 (V∗(s)) の間には、以下の関係があります。
V∗(s)=amaxQ∗(s,a)
これは、「ある状態の最高の価値(V値)は、その状態で取りうる最も良い行動を選んだときの価値(最大のQ値)と同じ」という意味です。直感的にも理解しやすいですね。
Q学習:試行錯誤でQ値を賢く更新する方法【G検定最重要】
さて、AIが最適な行動をとるためには「正しいQ値」が必要だとわかりました。でも、最初から正しいQ値を知っているわけではありません。
そこで登場するのが「Q学習(Q-learning)」です! Q学習は、AIが実際に迷路の中を動き回りながら(試行錯誤しながら)、経験を通してQ値をどんどん更新(学習)していくための代表的なアルゴリズムです。
Qテーブル:Q値を記録する「カンニングペーパー」
Q学習では、まず「Qテーブル」という表を用意します。これは、すべての「状態」と「行動」の組み合わせに対するQ値を記録しておくための、いわばAIの「カンニングペーパー」です。
【Qテーブルのイメージ図】
| 状態 \ 行動 | 上へ進む | 下へ進む | 右へ進む | 左へ進む |
| スタートマス | 0 | 0 | 0 | 0 |
| 通路マスA | 0 | 0 | 0 | 0 |
| ゴール前マス | 0 | 0 | 0 | 0 |
| … | … | … | … | … |
| (行き止まり) | 0 | 0 | 0 | 0 |
最初は、すべてのQ値をゼロや適当な小さな値で初期化しておきます。ここから学習スタートです!
Q学習の心臓部!ベルマン方程式に基づく更新【G検定ポイント】
AIはQテーブルを見ながら、次にとる行動を決めます(どうやって決めるかは後述します)。そして、行動し、報酬を受け取り、次の状態に移ります。この一連の経験を使って、Qテーブルの値を更新していくのです。
Q学習の更新式は以下のようになります。これはG検定で非常によく問われるので、式の形と意味をしっかり理解しましょう!
Q(s,a)←Q(s,a)+α[今回の経験から得た目標値r+γa′maxQ(s′,a′)−今の推定値Q(s,a)]
【式の読み解き】
- Q(s,a): 更新したいQ値(状態 s で行動 a をとったときの、今のQ値)
- ←: この矢印は「左辺の値を右辺の値で更新する」という意味です。
- α: 学習率(アルファ)。0より大きく1以下の値。新しい情報をどれくらい強く反映させるかの度合い。αが小さいと慎重に少しずつ更新、大きいと大胆に更新します。
- r: 行動 a をとった結果、実際にもらえた報酬 (Reward)。
- γ: 割引率(未来の報酬をどれだけ重視するか)。
- s′: 行動 a をとった結果、次に遷移した状態。
- maxa′Q(s′,a′): 次の状態 s′ において、取りうる行動の中で最も高いQ値を持つ行動を選んだ場合のQ値。(次の状態での最善の期待値)
- r+γmaxa′Q(s′,a′): 「実際にもらった報酬 r」と「次の状態で期待できる最大の未来の報酬(割引あり)」の合計。これが、今回の経験から計算される「Q値は本来これくらいが理想だよね」という目標値 (Target) になります。
- […]: カッコの中身全体 (目標値−今の推定値) は、TD誤差 (Temporal Difference Error) と呼ばれます。目標値と現在の推定値のズレを表します。
【Q学習の更新を図解イメージ】
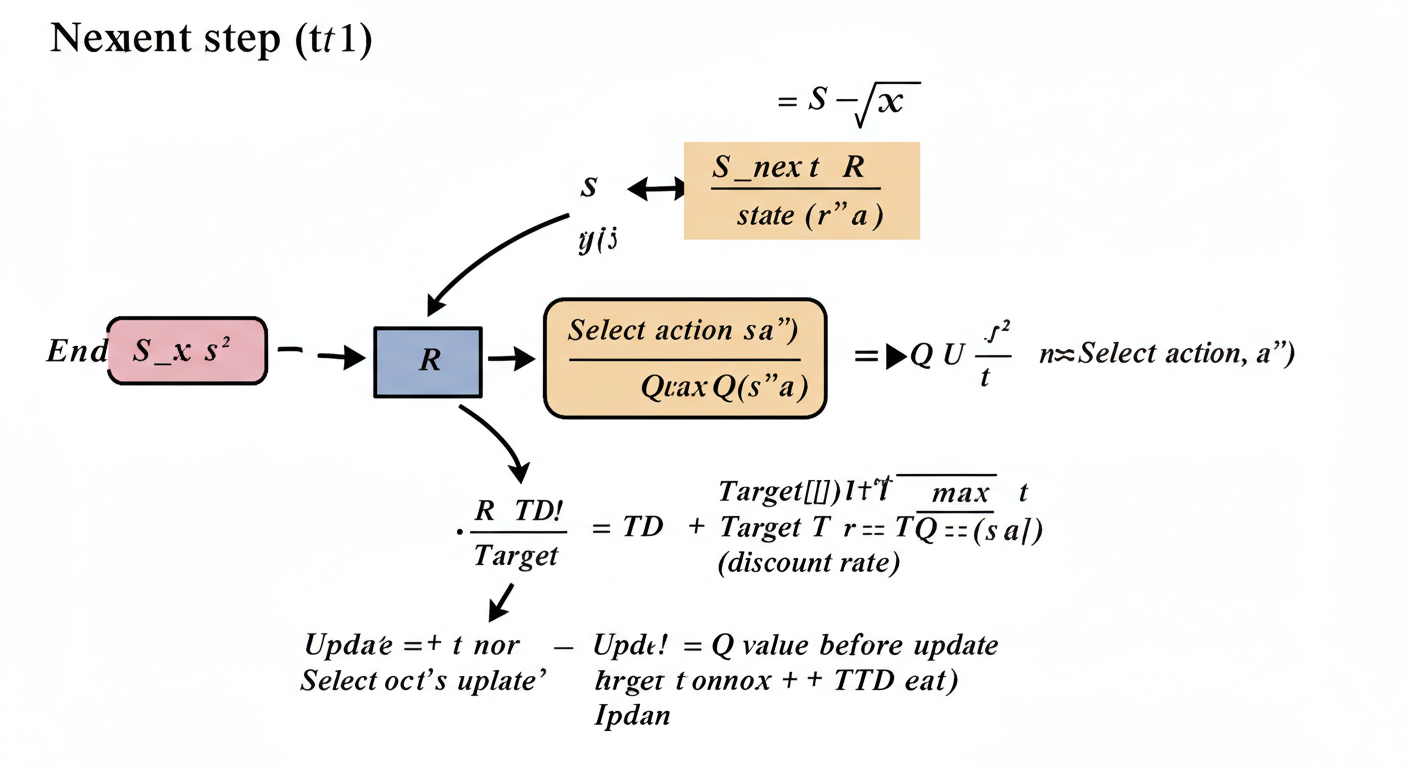
【超訳】 「やってみたら、思ったより良かった(or 悪かった)な。じゃあ、今のQ値の予想を、今回の経験(実際にもらった報酬+次の状態でのベストな期待値)にちょっと近づけて修正しておこう!」
この更新を何度も何度も繰り返すことで、Qテーブルの値が徐々に「真の価値」に近づいていき、AIは賢くなっていくのです。
Q学習のアルゴリズムの流れ
Q学習は、ざっくり以下の流れで進みます。
- 初期化: Qテーブルのすべての値をゼロなどで初期化する。
- エピソード開始: AIをスタート地点(初期状態 s)に置く。
- 行動選択: 今いる状態 s で、何らかの方法(後述のε-greedy法など)で行動 a を選ぶ。
- 実行と観測: 選んだ行動 a を実行し、報酬 r と次の状態 s′ を観測する。
- Q値更新: 上で説明したQ学習の更新式を使って、Q(s,a) を更新する。
- 状態更新: 次の状態 s′ を現在の状態 s とする (s←s′)。
- 繰り返し: ゴールするなどの終了条件を満たすまで、ステップ3〜6を繰り返す。
- エピソード繰り返し: ステップ2〜7を何度も(多数のエピソード)繰り返すことで、Qテーブル全体を学習させる。
この試行錯誤のループを通じて、AIは最適な行動戦略(=最適なQテーブル)を獲得していきます。
賢く学習するための工夫:探索と活用のバランス【G検定ポイント】
Q学習を進める上で、一つ大きな問題があります。それは「探索(Exploration)」と「活用(Exploitation)」のバランスをどう取るか、という問題です。
- 活用: 今のQテーブルを見て、一番Q値が高い(=一番良さそうだと思われる)行動を選ぶこと。
- 探索: Q値が高くない行動も、あえて試してみること。まだ知らないだけで、実はすごく良い行動かもしれないから。
もし「活用」ばかりしていると、最初にたまたま見つけたルートが最適だと勘違いしてしまい、もっと良いルート(未知のルート)を見つけるチャンスを逃してしまうかもしれません。迷路の例で、いつも同じ道を通るようなものです。
かといって、「探索」ばかりしていては、いつまでたってもゴールに効率よくたどり着けません。
【G検定ポイント】 効率よく学習するためには、「活用」でこれまでの知識を活かしつつ、「探索」で新たな発見を求める、このバランスが非常に重要です。この「探索と活用のトレードオフ」は強化学習における普遍的な課題です。
ε-greedy(イプシロン・グリーディ)法とは?
このバランスを取るための最もシンプルで有名な方法が「ε-greedy(イプシロン・グリーディ)法」です。
- 確率 ϵ (イプシロン、例えば 0.1 = 10% のような小さな確率) で、ランダムに行動を選ぶ(探索)
- 確率 1−ϵ (例えば 0.9 = 90%) で、現在のQ値が最も高い行動を選ぶ(活用)
【イメージ】 「普段(90%の確率)は一番賢いと思う手を選ぶけど、たまに(10%の確率)は気分転換に違う手を試してみるか!」
多くの場合、学習の初期段階では ϵ を大きめ(探索を多めに)にして、学習が進むにつれて ϵ を徐々に小さくしていきます(最適な行動を活用する割合を増やす)。
【G検定ポイント】 ε-greedy法は、探索と活用のバランスを取るための代表的な手法として覚えておきましょう。
DQN(Deep Q-Network):もっと賢く!ディープラーニングとの融合【G検定ポイント】
Q学習とQテーブルは強力ですが、弱点もあります。それは、状態や行動の種類がものすごく多い問題には対応しきれないことです。
例えば、
- 将棋や囲碁:盤面のパターン(状態)は天文学的な数!
- ビデオゲーム:画面のピクセル情報(状態)は膨大!
こんな場合にQテーブルを作ろうとすると、メモリがいくらあっても足りませんし、すべての状態を経験することも不可能です。
そこで登場したのが「DQN(Deep Q-Network)」です! DQNは、Q学習にディープラーニング(深層学習)の技術を組み合わせることで、この問題を解決しました。
Qテーブルの限界とDQNの解決策
DQNは主に以下の工夫によって、複雑で大規模な問題にも対応できるようになりました。
- Q関数近似 (Function Approximation):
- 課題: 巨大すぎるQテーブルは作れない。
- 解決策: Qテーブルの代わりに、ニューラルネットワークを使ってQ値を推定(近似)する!
- 具体的には、「状態(例:ゲーム画面のピクセル情報)」をニューラルネットワークに入力すると、「各行動に対するQ値」が出力されるようなネットワーク(Qネットワーク)を学習させます。
- これにより、未知の状態に対しても、ある程度「それっぽい」Q値を計算できるようになります。
- 経験リプレイ (Experience Replay):
- 課題: 強化学習の経験データ(状態, 行動, 報酬, 次の状態の組)は時系列的に連続しており、そのまま学習に使うとデータ間の相関が高すぎて学習が不安定になりやすい。
- 解決策: 過去の経験データ (s,a,r,s′) を一度大きなメモリ(リプレイバッファ)にためておき、学習時にはそこからランダムにいくつか取り出して(ミニバッチ学習)、ニューラルネットワークの学習に使う。
- これにより、データの相関が低減され、学習が安定しやすくなります。
- ターゲットネットワーク (Target Network):
- 課題: Q学習の更新式では、「目標値」の計算にもQネットワーク自身を使いますが、学習中のネットワークは頻繁に更新されるため、目標値が不安定になり、学習がうまく収束しないことがある。
- 解決策: Q値更新時の「目標値」を計算するためだけの、少し古い(定期的に同期される)別のQネットワーク(ターゲットネットワーク)を用意する。
- 目標値が安定することで、学習全体の安定性が向上します。
【G検定ポイント】 DQNは、①ニューラルネットワークによるQ関数近似、②経験リプレイ、③ターゲットネットワークという3つの主要な技術によって、従来のQ学習の限界を突破し、複雑なタスク(特にAtariのビデオゲームなど)で高い性能を発揮しました。これらのキーワードと概要は必ず押さえておきましょう!
(補足)SARSAとの違い:ちょっとマニアックな話
Q学習と非常によく似たアルゴリズムに「SARSA(サルサ)」があります。G検定で深く問われることは稀かもしれませんが、違いを知っておくと理解が深まります。
一番の違いはQ値の更新方法です。
- Q学習 (オフポリシー): 次の状態 s′ で取りうる最善の行動(Q値が最大になる行動)のQ値を使って更新する。
- Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
- SARSA (オンポリシー): 次の状態 s′ で実際に選択した行動 a′ のQ値を使って更新する。
- Q(s,a)←Q(s,a)+α[r+γQ(s′,a′)−Q(s,a)]
SARSAは、自分が実際にとっている行動方針(方策)に基づいて学習するため「オンポリシー」、Q学習は、次の行動は最善のものを選ぶと仮定して学習するため(実際にはε-greedyなどで違う行動をとることもある)、行動方針と学習方針が異なりうる「オフポリシー」と呼ばれます。
迷路の例で、崖っぷちを歩くような場合、Q学習は「落ちない限りは最短ルートがベスト」と考えるかもしれませんが、SARSAは「たまにランダム行動(探索)で崖から落ちるリスクがあるから、少し遠回りでも安全なルートの方が良いかも」と学習する傾向があります。
まとめ:G検定で押さえるべきQ値の重要ポイント
さて、Q値について詳しく見てきました!最後に、G検定対策として特に重要なポイントをまとめます。
- Q値とは?
- ある状態である行動をとった場合の、将来にわたる累積報酬の期待値。(行動価値関数)
- AIが最適な行動を選ぶための指標となる。
- Q値 vs V値
- Q値:状態と行動のペアの価値。行動選択に使う。
- V値:状態そのものの価値。
- V∗(s)=maxaQ∗(s,a) の関係。
- Q学習
- 試行錯誤を通じてQ値を学習する代表的なアルゴリズム。
- 更新式は最重要! 各要素の意味(学習率α, 割引率γ, 報酬r, 次の最大Q値)を理解する。
- Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
- 探索と活用のトレードオフ
- 効率的な学習には、既知の良い手を使う「活用」と、未知の手を試す「探索」のバランスが不可欠。
- 代表的な手法はε-greedy法。
- DQN (Deep Q-Network)
- Q学習をディープラーニングで発展させたもの。大規模な問題に対応。
- Q関数近似(ニューラルネットワーク)
- 経験リプレイ
- ターゲットネットワーク
- これらの技術でQ学習の限界を克服。
これらのポイントをしっかり復習して、G検定の問題に自信を持って答えられるようにしておきましょう!
さいごに:Q値から広がる強化学習の世界
今回は、強化学習の基本的な概念である「Q値」について、G検定対策を意識しながら解説しました。
AIがまるで自分で考えているかのように、試行錯誤しながら賢くなっていく仕組み、少しイメージできたでしょうか?
Q値やQ学習は、強化学習の基礎であり、ここからさらに発展した多くのアルゴリズム(DDPG, A3Cなど)のベースにもなっています。今回学んだ知識は、G検定合格はもちろん、その先のAIやデータサイエンスの世界を深く理解するための大切な一歩となるはずです。
ぜひ、この記事をきっかけに、強化学習の面白い世界をもっと探求してみてくださいね。
G検定合格、そしてその先の学びに向けて、応援しています!
コメント