
「AIってどうやって最適な行動を決めているんだろう?」 「G検定の勉強を始めたけど、強化学習の用語が難しい…」
そんな風に感じていませんか? 特に「状態価値関数」という言葉、なんだか難しそうですよね。
でも、ご安心ください! この状態価値関数は、AIが賢く行動するための 「羅針盤」 のようなもので、強化学習を理解する上で欠かせない、とても重要な概念なんです。そして、G検定でも頻出の重要キーワードでもあります。
この記事では、G検定の学習を始めたばかりのあなたに向けて、
- 状態価値関数って、そもそも何なのか
- 強化学習の心臓部「ベルマン方程式」とは?
- どうやって計算するの?代表的な方法は?
- G検定でどこが問われるの?
といった点を、「すごろく」の例えやイラスト(イメージ)を使いながら、ゼロから分かりやすく解説していきます。この記事を読み終える頃には、きっと状態価値関数の基本が理解でき、G検定対策への自信も深まっているはずです!
そもそも「状態価値関数」って何? ~すごろくでイメージをつかもう!~
ゴールに近いマスは「価値が高い」?
まずは、身近な「すごろく」を思い浮かべてみてください。

- スタート地点
- いくつかのマス
- 途中に「1回休み」のマス
- ゴール地点(大きな報酬あり!)
さて、このすごろくで「良いマス」と「悪いマス」はどこでしょうか?
- ゴール直前のマス: あと一歩でゴール!報酬が目前なので、すごく「良いマス」ですよね。
- 「1回休み」のマス: ここに止まると損なので、「悪いマス」と言えそうです。
- スタート直後のマス: ゴールまで遠いので、ゴール直前のマスほど良くはないかもしれません。
このように、そのマス(状態)にいると、最終的にどれくらい嬉しい結果(報酬)が期待できるか を数値で表したものが、ざっくり言うと「状態価値」です。そして、それを計算するための関数が「状態価値関数」なのです。
ゴールに近いほど「価値が高い」、ペナルティがあるマスは「価値が低い」という直感が、状態価値関数の基本的な考え方につながります。
状態価値関数 V_pi(s) の定義 ~AIの「期待度」を数値化~
もう少し正確に定義しましょう。
状態価値関数 V_pi(s) とは、
「ある状態 s にいるときに、特定の戦略(方策 pi)に従って行動し続けた場合に、将来にわたって得られる報酬の合計(累積報酬)の期待値」
を表す関数です。
数式では、以下のように書かれます。
Vπ(s)=Eπ[Rt∣st=s]
…いきなり数式が出てきて戸惑ったかもしれませんね。大丈夫、記号の意味を一つずつ見ていきましょう。
- V: 価値(Value)を表します。関数の名前です。
- pi (パイ): AIの行動戦略(方策、ポリシー) を表します。どんなルールで行動するか、ということです。(後で詳しく説明します)
- s: 状態 (State) を表します。すごろくで言えば、「今いるマス」のことです。
- E_pi : 方策 pi に従った場合の期待値 (Expectation) を表します。「平均的にどれくらいの報酬が見込めるか」という意味です。サイコロの目は運次第ですが、何度もプレイすれば平均的な結果が見えてきますよね。
- R_t: 時刻 t 以降に得られる報酬の総和(累積報酬, Return) を表します。ゴールした時の報酬だけでなく、途中で得られる小さな報酬なども含みます。s_t=s は「時刻 t の状態が s である」という条件を示します。
つまり、この関数 V_pi(s) は、「このマス(状態 s)から、この戦略(pi)で進めたら、平均してどれくらいの合計報酬(R_t)がゲットできそうかな?」 という期待度を数値で示してくれるものなのです。
将来の報酬は割り引く? ~割引率 gamma の役割~
先ほどの累積報酬 R_t は、もう少し詳しく書くと以下のようになります。
Rt=rt+1+γrt+2+γ2rt+3+…=k=0∑∞γkrt+k+1
ここで、r_t+1 は次のステップでもらえる即時の報酬、r_t+2 はその次のステップでもらえる報酬… を表します。
注目してほしいのは、gamma (ガンマ) という記号です。これは 割引率 (Discount rate) と呼ばれ、通常 $0 \\le \\gamma \< 1$ の値を取ります。(例えば 0.9 など)
なぜ将来の報酬を割り引くのでしょうか? 主な理由は2つあります。
- 不確実性: 未来のことは不確かです。すごろくでも、次のサイコロで何が出るかわかりません。遠い未来の報酬ほど、手に入るかどうかわからないので、少し価値を低く見積もります。
- 即時報酬の重視: 一般的に、すぐにもらえる報酬の方が、後でもらえる報酬よりも価値が高いと考えられます。(今すぐ1000円もらうのと、1年後に1000円もらうのでは、今すぐの方が嬉しいですよね?)
gamma が 0 に近いほど「今すぐの報酬」を重視し、1 に近いほど「未来の報酬」まで考慮に入れるようになります。この gamma の設定は、AIの行動特性(目先の利益を追うか、長期的な利益を狙うか)に影響を与えます。
AIの行動ルール「方策 pi」
状態価値関数 V_pi(s) の pi は、方策 (Policy) と呼ばれるもので、AIの「行動ルール」や「戦略」のことです。
すごろくの例で言えば、
- 方策A: どんなマスにいても、ひたすらサイコロを振って進む。
- 方策B: 「1回休み」のマスの手前では、わざと小さい目が出るようにサイコロを振る(もしそんなことができれば!)。
このように、方策が変われば、同じマス(状態 s)にいても、その後の行動や得られる報酬の期待値が変わってきます。だから、状態価値関数は必ず特定の方策 pi とセットで考えます。「方策 pi のもとでの状態 s の価値」が V_pi(s) なのです。
【図解イメージ】状態と価値の関係
ここで、簡単なすごろく盤(格子世界)で状態価値を可視化してみましょう。
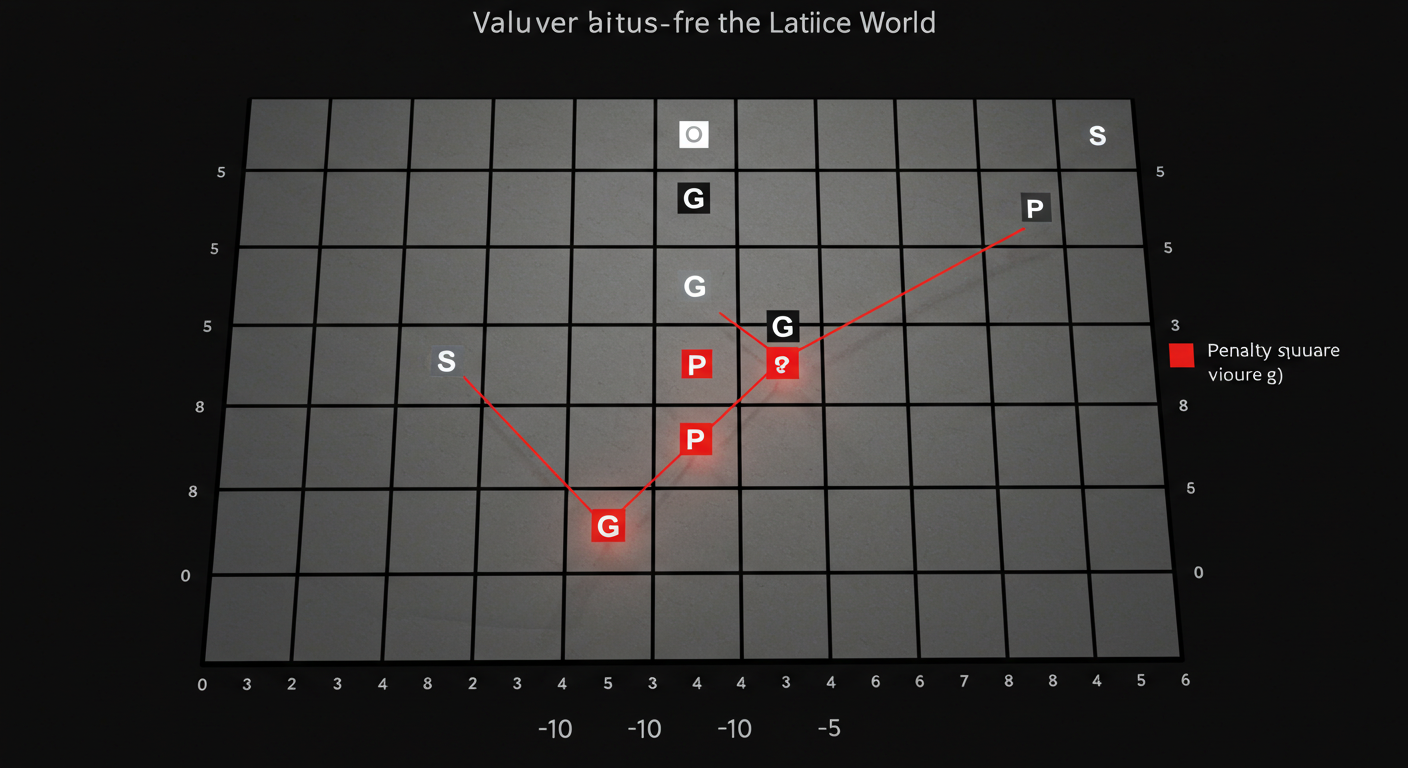
- 5×5 程度のマス目
- スタート地点 (S)
- ゴール地点 (G) に大きなプラスの価値 (例: +10)
- 途中のペナルティマス (P) にマイナスの価値 (例: -5)
- 他のマスには、ゴールからの距離やペナルティマスからの距離に応じて計算された価値が示されている。ゴールに近いマスほど価値が高く、ペナルティマスに近いほど価値が低い傾向が見える。
この図のように、各マス(状態)の「良さ」を数値(価値)で表現するのが状態価値関数です。AIは、この価値が高いマスを目指すように行動することで、効率的にゴール(報酬)にたどり着こうとします。
強化学習の心臓部!「ベルマン方程式」を理解しよう【G検定最重要】
さて、状態価値関数が「状態の良さ」を表すことは分かりました。では、その価値 V_pi(s) は具体的にどうやって計算すれば良いのでしょうか?
ここで登場するのが、強化学習の理論において非常に重要な ベルマン方程式 (Bellman Equation) です。G検定でも超重要ポイントなので、しっかり理解しましょう!
「今のマスの価値」はどう決まる? ~となりのマスとの関係~
ベルマン方程式の基本的な考え方は、実はとてもシンプルです。
「今の状態の価値は、次に取る行動によって得られる『即時報酬』と、その行動の結果たどり着く『次の状態の価値(割引後)』の期待値(平均)で決まる」
というものです。
すごろくで例えると、
「今いるマス A の価値」 = (サイコロを振ってマス B に行く確率) × (マス B に行くまでにもらえる報酬 + マス B の価値 × 割引率 gamma)
- (サイコロを振ってマス C に行く確率) × (マス C に行くまでにもらえる報酬 + マス C の価値 × 割引率 gamma)
- … (他の可能な移動についても同様)
というように、ある状態の価値を、その次の状態の価値を使って表すことができる、というのがポイントです。この関係性を数式にしたものがベルマン方程式です。
【図解イメージ】ベルマン方程式の概念図
この関係性を図で見てみましょう。
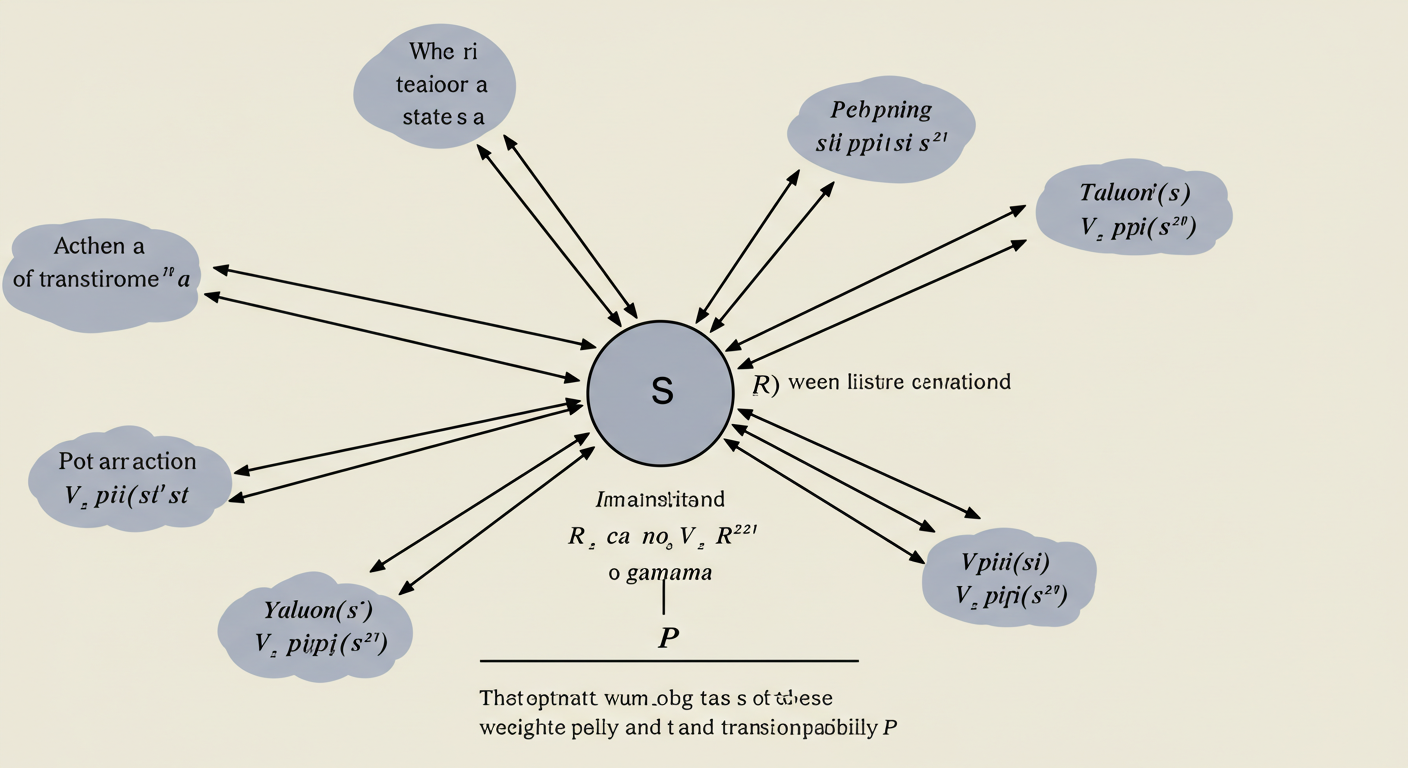
- 中心に現在の状態 s がある。
- 状態 s から、いくつか矢印(行動 a を表す)が出ている。
- 各矢印の先には、遷移後の状態 s′ がある。
- 状態 s から行動 a を取って状態 s′ に遷移する際には、即時報酬 R が得られることが示されている。
- 遷移後の状態 s′ には、その状態の価値 V_pi(s′) が関連付けられている(少し小さく描画するなどして、割引率 gamma がかかることを示唆)。
- 状態 s の価値 V_pi(s) は、これらの「即時報酬 R」と「割引された次の状態の価値 gammaV_pi(s′)」を、方策 pi と遷移確率 P で重み付けして合計したものとして計算される、という関係性が矢印などで示されている。
この図は、状態 s の価値 V_pi(s) が、そこから取りうる行動 a、その結果得られる即時報酬 R、そして遷移先の状態 s′ の価値 V_pi(s′) に依存していることを視覚的に示しています。
ベルマン方程式の正体 ~数式と意味を徹底解説~
では、ベルマン方程式を数式で見てみましょう。状態価値関数 V_pi(s) についてのベルマン方程式は以下のように表されます。
Vπ(s)=a∑π(s,a)s′∑Pss′a[Rss′a+γVπ(s′)]
難しそうに見えますが、パーツごとに分解すれば理解できます。
- V_pi(s): 今いる状態 s の価値(求めたいもの)
- sum_a: 「すべての可能な行動 a について合計する」という意味の記号(シグマ)。すごろくなら、サイコロの目に対応する行動すべて。
- pi(s,a): 状態 s で行動 a を選択する確率(方策 pi による)。例えば、普通のサイコロなら、1~6の目が出る確率はそれぞれ 1/6 ですね。
- sum_s′: 「すべての可能な次の状態 s′ について合計する」という意味。行動 a を取った結果、どの状態に遷移する可能性があるか、すべて考えます。
- Pa_ss′: 状態 s で行動 a を取ったときに、状態 s′ に遷移する確率。すごろくで特定の目が出れば、基本的には次のマスは一つに決まりますが(確率1)、ゲームによっては「確率 1/2 で A へ、確率 1/2 で B へ」のように、遷移先が確率的に決まる場合もあります。
- Ra_ss′: 状態 s で行動 a を取り、状態 s′ へ遷移したときにすぐにもらえる報酬(即時報酬)。ゴールマスに到達したら大きな報酬、何もなければ報酬 0、など。
- gamma: 割引率。将来の価値を少し割り引くための係数。
- V_pi(s′): 次の状態 s′ の価値。ここがポイントで、現在の価値を計算するために、未来の価値を使っています。
この式全体を日本語で意訳すると、
「状態 s の価値 V_pi(s) は、『状態 s で行動 a を確率 pi(s,a) で選び、その結果、確率 Pa_ss′ で状態 s′ に移って即時報酬 Ra_ss′ をもらい、さらにその先の状態 s′ の価値 V_pi(s′) を gamma で割り引いたものを足し合わせたもの』を、考えられるすべての行動 a と遷移先 s′ について平均(期待値)を取ったもの」
となります。長いですが、現在の価値と未来の価値の関係性を示していることが分かればOKです!
なぜベルマン方程式が重要なのか?
この方程式が重要な理由は、大きく2つあります。
- 価値計算の基礎: この方程式を使うことで、各状態の価値を繰り返し計算し、真の価値に近づけていくことができます(後述する動的計画法などで使われます)。
- 強化学習アルゴリズムの根幹: Q学習など、多くの実践的な強化学習アルゴリズムが、このベルマン方程式の考え方をベースにしています。
つまり、ベルマン方程式は、状態価値関数を理解し、計算するための理論的な支柱となっているのです。
【G検定Point】ベルマン方程式は必ず押さえよう!
G検定では、ベルマン方程式の数式の意味を理解しているかが問われる可能性があります。
- 式を見て、どの項が「即時報酬」で、どの項が「次の状態の価値」で、どの項が「割引率」かなどを説明できるようにしておきましょう。
- 「現在の価値が、次のステップの価値を使って再帰的に定義される」という関係性を理解しておくことが重要です。
- なぜこの方程式が強化学習で重要なのか(価値計算の基礎、アルゴリズムの根幹)も説明できると完璧です。
数式を丸暗記するのではなく、各項の意味と、式全体の構造(現在の価値と未来の価値の関係) をしっかり掴んでください。
「状態」だけ見る?「行動」も見る? ~行動価値関数 Q_pi(s,a) との違い~
状態価値関数 V_pi(s) と非常によく似た概念に、行動価値関数 (Action Value Function) Q_pi(s,a) があります。この二つの違いを理解することもG検定では重要です。
行動価値関数 Q_pi(s,a) とは? ~特定の行動の「良さ」を評価~
行動価値関数 Q_pi(s,a) (キューかんすう、と読みます)は、
「ある状態 s で、特定の行動 a を取った後、方策 pi に従って行動し続けた場合に、将来にわたって得られる報酬の合計(累積報酬)の期待値」
を表します。数式では以下の通りです。
Qπ(s,a)=Eπ[Rt∣st=s,at=a]
状態価値関数 V_pi(s) との違いは、「特定の行動 a を取った場合」という条件が加わっている点です。
- V_pi(s): 状態 s の総合的な良さ(その状態から取りうる様々な行動を平均的に考えた価値)
- Q_pi(s,a): 状態 s で行動 a を選択すること自体の良さ
すごろくで言えば、
- V_pi(textマスX): マスXにいること自体の価値(ここからサイコロを振ったら平均的にどれくらい嬉しいか)
- Q_pi(textマスX,textサイコロで3を出す): マスXで「サイコロで3を出す」という行動を取った場合の価値(3進んだ先のマスが良いマスなら高い価値になる)
となります。
状態価値関数 V と行動価値関数 Q の違い早わかり表
| 特徴 | 状態価値関数 V_pi(s) | 行動価値関数 Q_pi(s,a) |
| 評価対象 | 状態 s の良さ | 状態 s で行動 a を取ることの良さ |
| 入力変数 | 状態 s | 状態 s と行動 a |
| 意味合い | その状態にいると、将来どれくらい良いか? | その状態でその行動をすると、将来どれくらい良いか? |
| 使い所例 | 環境モデルが分かっている場合の方策評価 | 環境モデルが未知でも最適な行動を選びたい場合 (Q学習など) |
V と Q の関係式 ~つながりを理解する~
状態価値関数 V と行動価値関数 Q の間には、以下のような関係があります。
Vπ(s)=a∑π(s,a)Qπ(s,a)
これは、「状態 s の価値は、その状態で取りうる各行動 a の価値 Q_pi(s,a) を、その行動を取る確率 pi(s,a) で重み付けして合計したもの(期待値)」 という意味です。
つまり、状態 s から様々な行動 a を選択した場合のそれぞれの価値 Q_pi(s,a) を、方策 pi に従って平均すれば、その状態自体の価値 V_pi(s) になる、という自然な関係を表しています。
【G検定Point】V と Q の違いと関係性を問われる!
G検定では、V と Q の定義の違い、そして両者の関係性を理解しているかが問われます。
- V は「状態」の価値、Q は「状態と行動のペア」の価値であることを明確に区別しましょう。
- V(s)=sum_api(s,a)Q(s,a) の関係式は重要なので、意味を理解しておきましょう。
- どちらの関数がどのような場面で使われるか(特に Q 関数がQ学習などで中心的な役割を果たすこと)もポイントです。
どうやって価値を計算するの? ~代表的な3つのアプローチ~
ベルマン方程式は価値の関係性を示しましたが、実際に未知の価値を計算するにはどうすれば良いのでしょうか? 主に3つのアプローチがあります。
計算方法の比較表(DP vs MC vs TD)
| アプローチ | 特徴 | メリット | デメリット | 環境モデル※ |
| 動的計画法 (DP) | ベルマン方程式を繰り返し使う | 正確な値が求まる(理論上) | 環境モデルが必要、計算量が多い | 必要 |
| モンテカルロ法 (MC) | 実際に何度も試行して平均を取る | 環境モデル不要、直感的 | 試行(エピソード)が終わるまで更新できない、分散が大きい | 不要 |
| 時間的差分学習 (TD) | DPとMCのいいとこ取り、1ステップ毎に更新 | 環境モデル不要、オンライン学習可能、効率が良い | 推定値を使って推定するためバイアスがある | 不要 |
※環境モデル:状態遷移確率 Pa_ss′ と報酬関数 Ra_ss′ が事前にすべて分かっていること。すごろくのルールが完全に分かっている状態。
アプローチ①:動的計画法(DP) ~地図が完璧にある場合~
動的計画法 (Dynamic Programming) は、環境モデル(すべての状態遷移確率と報酬)が既知の場合に使える強力な手法です。ベルマン方程式を更新式として利用し、全状態の価値を繰り返し計算することで、真の状態価値に収束させます。
イメージ: すごろくの全てのルール(どのマスからどのマスへ行けるか、報酬はいくつか)が書かれた完璧な地図を持っている状態で、地図を見ながら各マスの価値を何度も計算し直していく感じ。
アプローチ②:モンテカルロ法(MC) ~実際に何度もゴールしてみる~
モンテカルロ法 (Monte Carlo method) は、環境モデルが未知の場合でも使えます。実際にエージェント(プレイヤー)が何度も試行(エピソード、すごろくならスタートからゴールまで)を行い、各状態で得られた実際の累積報酬を集計して、その平均値を状態価値の推定値とします。
イメージ: すごろくのルールがよく分からなくても、とにかく何度もプレイしてみて、「このマスに止まった時は、平均してこれくらいのスコアでゴールできたな」という経験から価値を学習していく感じ。
アプローチ③:時間的差分学習(TD) ~一歩進むごとに学習~
時間的差分学習 (Temporal Difference learning) は、DPとMCの良いところを組み合わせたような手法で、環境モデルが未知でも使え、かつオンライン(1ステップごと)に学習を進められるのが大きな特徴です。Q学習など、現在の強化学習で広く使われているアルゴリズムの基礎となっています。
TD学習では、1ステップだけ行動してみて、得られた即時報酬と次の状態の現在の推定価値を使って、現在の状態の価値を更新します。ベルマン方程式と考え方は似ていますが、次の状態の真の価値ではなく、現在の推定値を使う点が異なります。
代表的な更新式 (TD(0)): V(s)←V(s)+α[r+γV(s′)−V(s)] ここで、alpha (アルファ) は学習率(どれくらい更新を反映させるか)、[r+gammaV(s′)−V(s)] の部分は TD誤差 と呼ばれ、「実際に得られた価値(即時報酬 r + 次の推定価値 gammaV(s′))」と「現在の推定価値 V(s)」の差を表します。この誤差を小さくするように学習を進めます。
イメージ: すごろくを1マス進むたびに、「思ったより良いマスに着いたな(TD誤差がプラス)」とか「思ったより悪いマスだったな(TD誤差がマイナス)」とかを判断し、その都度、元のマスの価値の評価を少し修正していく感じ。
【G検定Point】各手法の特徴と違いを理解しよう
G検定では、DP, MC, TD のそれぞれの特徴、メリット・デメリット、そしてどのような状況で使われるかを理解しておくことが重要です。
- 環境モデルが必要か不要か は大きな違いです。
- いつ価値を更新するか(DP: 全体計算、MC: エピソード終了後、TD: 1ステップごと)もポイントです。
- TD学習が現在の主流アルゴリズム(Q学習など)の基礎となっている点も押さえておきましょう。
【実践】簡単な格子世界(すごろく盤)で価値計算をイメージ!
理論だけだと難しいので、簡単な例で状態価値がどう計算されるか見てみましょう。
問題設定:シンプルなすごろく盤
以下のような3×3の格子世界(すごろく盤)を考えます。
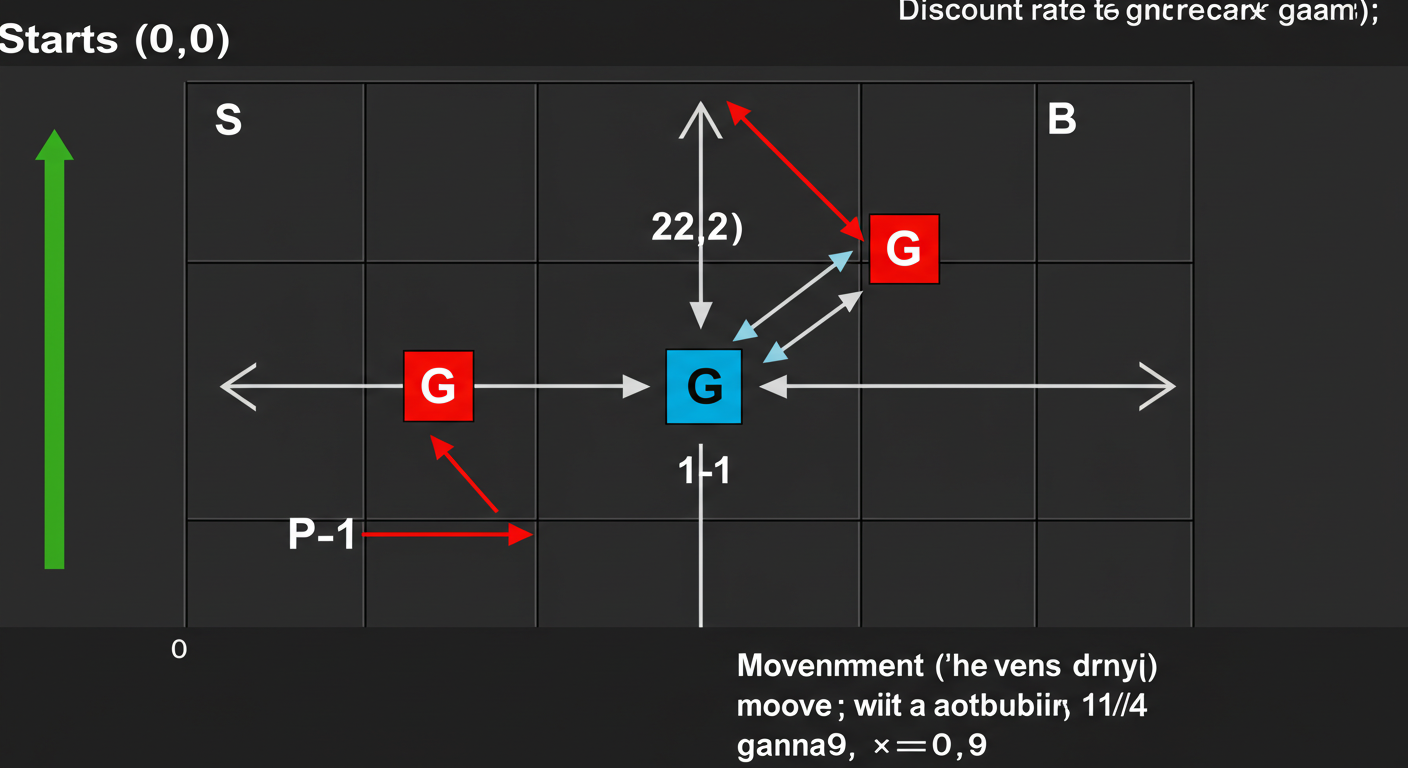
- マス (0,0) がスタート (S)
- マス (2,2) がゴール (G) で、ここに到達すると報酬 +10
- マス (1,1) はペナルティ (P) で、ここに到達すると報酬 -5
- 他のマスへの移動では報酬 0
- 行動は上下左右の4方向。盤面の外には出られない。
- 方策は「ランダム」(上下左右に等確率 1/4 で移動)とする。
- 割引率 gamma=0.9 とする。 <br>
この設定で、各マス(状態)の価値 V_pi(s) を計算するとどうなるでしょうか?
【図解イメージ】格子世界の価値マップ(計算結果例)
ベルマン方程式を使った計算(例えばTD学習や動的計画法)を繰り返していくと、最終的に各マスの価値は以下のようなイメージになります。
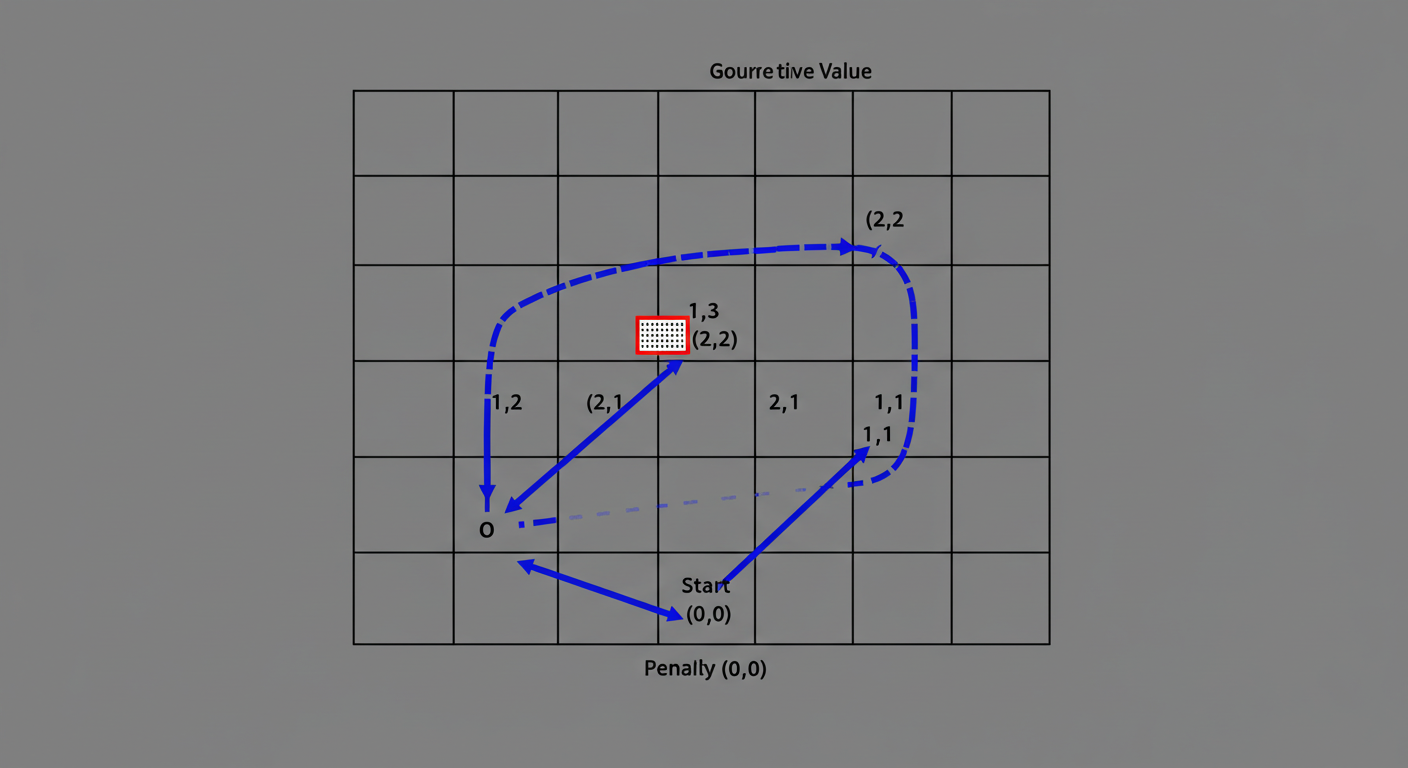
- 各マスに計算された価値が表示されている。
- ゴール (2,2) に最も近いマス (例: (1,2), (2,1)) の価値が高くなっている。
- ペナルティマス (1,1) は価値がマイナスになっている。
- スタート (0,0) など、ゴールから遠くペナルティマスに近いマスは価値が低めになっている。
- 全体として、ゴールに近づくほど価値が高く、ペナルティマスを避けるような価値分布になっている。
このように、状態価値を計算することで、どのマスが「良い」か、どのマスが「悪い」かが一目瞭然になりますね。
Pythonコードで価値計算(ロジック解説付き)
実際に状態価値を計算する雰囲気を掴むために、簡単なPythonコード(TD学習の一部のようなイメージ)を見てみましょう。ここでは、ある状態 s から行動 a を取って、次の状態 s_prime になり、報酬 r を得た場合に、状態 s の価値 V[s] を更新する部分のロジックを示します。
Python
import numpy as np
def update_state_value(V, s, r, s_prime, alpha, gamma, is_terminal):
“””
状態価値をTD学習で更新する。
Args:
V: 状態価値テーブル (NumPy配列)
s: 現在の状態 (整数)
r: 報酬 (数値)
s_prime: 次の状態 (整数)
alpha: 学習率 (0 < alpha <= 1)
gamma: 割引率 (0 <= gamma <= 1)
is_terminal: 次の状態が終端状態かどうか (bool)
Returns:
V: 更新された状態価値テーブル
“””
# 現在の状態 s の価値を取得
current_value = V[s]
# 次の状態 s_prime の価値を取得 (次の状態が終端状態なら next_value = 0)
next_value = 0 if is_terminal else V[s_prime]
# TDターゲット(目標となる価値)の計算
# TDターゲット = 即時報酬 + 割引率 * 次の状態の価値
td_target = r + gamma * next_value
# TD誤差(目標との差)の計算
td_error = td_target – current_value
# 状態価値の更新
# 新しい価値 = 現在の価値 + 学習率 * TD誤差
V[s] = current_value + alpha * td_error
return V
# — 初期化 —
# 状態価値テーブルの初期化 (例: 3×3グリッドなら9状態)
num_states = 9
V = np.zeros(num_states)
# ハイパーパラメータ設定
alpha = 0.1 # 学習率
gamma = 0.9 # 割引率
# — シミュレーション —
# 状態遷移と報酬の例 (実際には環境から得られる)
# (s, r, s_prime, is_terminal) のタプルで表現
# 例: 状態0から行動して報酬-1を得て状態1に遷移、状態8は終端状態
transitions = [
(0, -1, 1, False),
(1, 0, 2, False),
(2, -1, 5, False),
(3, -1, 4, False),
(4, 0, 5, False),
(5, 10, 8, True),
(6, -1, 7, False),
(7, 0, 8, True),
(0, -1, 3, False),
(3, 0, 6, False),
(6, 0, 8, True),
(1, -1, 4, False),
(4, 0, 7, False),
(2, -1, 5, False),
(5, 0, 8, True),
]
# 学習ループ
num_episodes = 100 # エピソード数
for episode in range(num_episodes):
print(f”Episode {episode+1}/{num_episodes}”)
for s, r, s_prime, is_terminal in transitions:
V = update_state_value(V, s, r, s_prime, alpha, gamma, is_terminal)
print(f” State: {s}, Reward: {r}, Next State: {s_prime}, Terminal: {is_terminal}”)
print(f” Updated V: {V}”)
# 学習後の状態価値テーブル
print(“\nFinal State Value Table:”)
print(V)
コード解説(ロジック中心)高度のため難しいと感じた人は飛ばしてください:
全体の流れ
- 状態価値テーブルの初期化:
- num_states = 9: 状態の数を9と定義しています。これは、例えば3×3のグリッドワールドを想定しているようなイメージです。
- V = np.zeros(num_states): 各状態の価値を格納するテーブル V を作成し、初期値はすべて0に設定しています。
- ハイパーパラメータの設定:
- alpha = 0.1: 学習率。新しい情報(TD誤差)をどれだけ現在の価値に反映させるかを調整するパラメータです。0.1なので、10%だけ反映させます。
- gamma = 0.9: 割引率。将来の報酬をどれだけ割り引いて考えるかを調整するパラメータです。0.9なので、1ステップ先の報酬は0.9倍、2ステップ先は0.9*0.9倍というように割り引かれます。
- 状態遷移と報酬の定義:
- transitions: 状態遷移と報酬の例を定義したリストです。
- (s, r, s_prime, is_terminal) のタプルで、以下の情報を表します。
- s: 現在の状態
- r: 行動によって得られた報酬
- s_prime: 次の状態
- is_terminal: 次の状態が終端状態かどうか(True/False)
- 例:(0, -1, 1, False) は、「状態0から行動して報酬-1を得て状態1に遷移し、状態1は終端状態ではない」ことを意味します。
- 例:(5, 10, 8, True) は、「状態5から行動して報酬10を得て状態8に遷移し、状態8は終端状態である」ことを意味します。
- 学習ループ:
- num_episodes = 100: 学習を繰り返す回数(エピソード数)です。
- for episode in range(num_episodes):: エピソードごとにループします。
- for s, r, s_prime, is_terminal in transitions:: 各エピソード内で、transitions に定義された状態遷移を順番に処理します。
- V = update_state_value(V, s, r, s_prime, alpha, gamma, is_terminal): update_state_value 関数を呼び出して、状態価値を更新します。
- update_state_value 関数の詳細:
- この関数がTD学習の核心部分です。
- current_value = V[s]: 現在の状態 s の価値を取得します。
- next_value = 0 if is_terminal else V[s_prime]: 次の状態 s_prime の価値を取得します。ただし、is_terminal が True の場合は、終端状態なので next_value は 0 になります。
- td_target = r + gamma * next_value: TDターゲットを計算します。これは、現在の状態の価値が最終的に向かうべき目標値です。
- r: 即時報酬(行動によってすぐに得られる報酬)
- gamma * next_value: 将来の報酬の期待値(次の状態の価値を割引率で割り引いたもの)
- td_error = td_target – current_value: TD誤差を計算します。これは、現在の価値とTDターゲットとの差です。
- V[s] = current_value + alpha * td_error: 状態価値を更新します。
- alpha * td_error: TD誤差に学習率を掛けたものが、価値の更新量になります。
- つまり、TD誤差が大きいほど、価値の更新量も大きくなります。
- 出力
- 各ステップで、状態、報酬、次の状態、終端状態かどうか、更新された状態価値を表示します。
- 最終的な状態価値テーブルを表示します。
ロジックのポイント
- TDターゲット: TD学習では、次の状態の価値を使って、現在の状態の価値を更新します。この「次の状態の価値」を考慮した目標値がTDターゲットです。
- TD誤差: 現在の価値とTDターゲットとの差がTD誤差です。この誤差を小さくするように価値を更新していきます。
- 学習率: 学習率が大きいほど、TD誤差の影響が大きくなり、価値の更新量も大きくなります。ただし、大きすぎると学習が不安定になる可能性があります。
- 割引率: 割引率が大きいほど、将来の報酬を重視します。割引率が0の場合は、即時報酬のみを考慮します。
- 終端状態: 終端状態はそれ以上遷移しない状態なので、価値は0とします。
この更新ステップを何度も繰り返すことで、状態価値の推定値 V は徐々に正確な値に近づいていきます。これがTD学習による価値計算の基本的な流れです。
状態価値関数の使い道 ~AIはどうやって賢くなる?~
さて、状態価値関数を計算できると、どんないいことがあるのでしょうか? AIが賢くなるプロセス(方策を改善していくプロセス)において、状態価値関数は重要な役割を果たします。
①方策の「成績表」を作る(方策評価)
まず、特定の方策 pi (行動ルール)に対して、その状態価値関数 V_pi(s) を計算することは、その方策の「良さ」を評価することにつながります。すべての状態 s について V_pi(s) を計算すれば、「この方策に従うと、どの状態から始めても平均的にこれくらいの報酬が得られる」という、方策全体の性能評価(成績表)ができるわけです。これを方策評価 (Policy Evaluation) と言います。
②もっと良い「戦略」に更新する(方策改善)
方策 pi の価値 V_pi(s) が分かったら、それを使って、もっと良い方策 pi′ を見つけることができます。
具体的には、各状態 s において、そこから可能な行動 a をすべて試し、行動価値関数 Q_pi(s,a) (現在の状態価値 V_pi を使って計算できる)が最大となるような行動 $a^\*$ を選ぶように、新しい方策 pi′ を作ります。
π′(s)=argamaxQπ(s,a)
(argmax_a は、Q_pi(s,a) を最大にするような行動 a を見つける操作)
つまり、「今の状態 s では、どの行動を取るのが一番価値が高い(Q値が最大)かな?」と考えて、一番良い行動を選択するようにルールを更新するのです。これを方策改善 (Policy Improvement) と言います。
③最強の「戦略」を見つけ出す(最適方策の探索)
そして、「①方策評価」と「②方策改善」を交互に繰り返していくことで、方策はどんどん改善され、最終的にはそれ以上改善できない最適方策 (Optimal Policy) $\\pi^\*$ と、それに対応する最適状態価値関数 (Optimal State Value Function) $V^\*(s)$ に収束していきます。
V∗(s)=πmaxVπ(s)
この最適方策 $\\pi^\*$ こそが、AIが目指すべき「最も賢い行動ルール」なのです。この一連の流れを方策反復法 (Policy Iteration) や価値反復法 (Value Iteration) と呼びます。
まとめ:状態価値関数をマスターしてG検定合格へ!
今回は、強化学習の基礎であり、G検定でも頻出の「状態価値関数」について、すごろくの例や図解イメージ、Pythonコード例を交えながら解説しました。
【今日の重要ポイント振り返り】
- 状態価値関数 V_pi(s) とは、ある状態 s から方策 pi に従ったときの「将来の累積報酬の期待値」であり、その状態の「良さ」を表す。
- 将来の報酬は割引率 gamma で割り引かれる。
- ベルマン方程式は、現在の状態価値と次の状態価値の関係を示す、強化学習の根幹をなす重要な式。G検定最重要ポイント!
- V_pi(s)=sum_api(s,a)sum_s′Pa_ss′[Ra_ss′+gammaV_pi(s′)]
- 式の各項の意味(即時報酬、次の状態価値、割引率など)を理解することが重要。
- 行動価値関数 Q_pi(s,a) は、「状態 s で行動 a を取ること」の価値を表す。V と Q の違いと関係性を理解しよう。
- 価値の計算方法には DP, MC, TD があり、それぞれの特徴(環境モデル要否、更新タイミング)を押さえる。TD学習はQ学習などの基礎。
- 状態価値関数は、方策評価や方策改善を通じて、AIが最適方策を見つけるために使われる。
状態価値関数は、一見すると数式が多くて難しく感じるかもしれませんが、その基本的な考え方(状態の良さを数値化する、現在の価値は未来の価値と関係している) を掴むことができれば、強化学習の他の概念(Q学習など)の理解もスムーズに進みます。
特に ベルマン方程式 は、強化学習理論の土台となる考え方ですので、G検定合格のためにも、ぜひその意味をしっかり理解しておきましょう!
この記事が、あなたのG検定学習の一助となれば幸いです。疑問点や分からないことがあれば、ぜひコメントなどで質問してくださいね。応援しています!
コメント