
「機械学習を勉強し始めたけど、データの特徴量が多すぎてよく分からない…」 「たくさんのデータの中に隠れている関係性やグループを、パッと見て理解できたらいいのに…」
データサイエンスの世界に足を踏み入れたばかりのあなたが、こんな風に感じているなら、この記事はきっと役に立ちます!
特に、アンケート結果、顧客の購買データ、センサーから集めた情報、画像データなど、たくさんの「特徴量」(データの項目や性質のことですね)を持つ高次元データを扱うとき、その全体像を掴むのは大変です。
そんな高次元データを、私たち人間が直感的に理解できる形に「見える化」してくれる魔法のようなテクニック、それが今回ご紹介するt-SNE(ティー・エス・エヌイー)です。
この記事を読めば、
- t-SNEって何?どんなことができるの?
- よく聞くPCAとはどう違うの?
- Pythonでどうやって使うの?(コピペOKなコード付き!)
- 使うときに気をつけることは?
といった疑問がスッキリ解消します。
さあ、あなたもt-SNEをマスターして、データの中に隠された宝物を見つけに行きましょう!
t-SNEってなに? ~複雑なデータを案内してくれる地図~
名前の意味と目的:似ているものは近くに!
t-SNEは、英語で「t-distributed Stochastic Neighbor Embedding」と書きます。…ちょっと難しい名前ですよね。でも、心配いりません!
簡単に言うと、t-SNEは 「元のデータの世界(高次元)で『ご近所さん』だったデータ同士は、新しい地図(低次元、主に2次元や3次元)の上でも『ご近所さん』になるように配置し直す」 ためのテクニックです。
たくさんの特徴量を持つデータを、人間が目で見て理解できる「可視化」に特化した「次元削減」(データの情報をなるべく保ったまま、特徴量の数を減らすこと)の一種と考えてください。
特徴:ラベルなしでOK!入り組んだ道も得意!
t-SNEは、機械学習の分類では「教師なし学習」というグループに入ります。これは、データに「これは0の画像」「これは1の画像」といった正解ラベルがなくても、データそのものの特徴だけを見て、似たもの同士を見つけ出せる、ということです。
そして、t-SNEが特に得意なのは、データ同士の関係が単純な直線では表せないような、複雑で入り組んだ「非線形」な構造を捉えることです。これが、他の次元削減手法、特にPCAとの大きな違いになります。(PCAについては後で詳しく説明しますね!)
【強調ポイント!】t-SNEは、この「非線形な構造」と「局所的な近傍関係(ご近所付き合い)」を捉えるのが非常にうまいのです!
t-SNEのすごいところ! (PCAと比べてみよう)
次元削減の手法として、t-SNEと並んでよく使われるのがPCA(主成分分析)です。「どっちを使えばいいの?」と迷うこともあるかもしれません。それぞれの得意なことを見ていきましょう。
PCA:データの「広がり」を最大限に見る方法
PCAは、データ全体がどの方向に一番「広がっているか」を見つけ出し、その方向を新しい軸(主成分)としてデータを表現し直すことで次元を削減します。データ全体の大まかな傾向や、まっすぐな(線形的な)関係を捉えるのが得意です。
t-SNE:データの「ご近所付き合い」を大切にする方法
一方、t-SNEは、データ全体の広がりよりも、個々のデータにとっての「ご近所さん」(似ているデータ)との関係を大切にします。入り組んだ道(非線形な構造)の先にあるご近所さんも、ちゃんと近くに配置しようと頑張ってくれます。だから、複雑なデータのクラスター(かたまり)をきれいに分けて表示するのが得意なんです。
どっちを使う?目的別ガイド
| 特徴ポイント | t-SNE (ご近所重視!) | PCA (全体重視!) |
| 得意なこと | 複雑なデータの可視化、クラスター発見 | 全体の傾向把握、ノイズ除去、特徴抽出 |
| 見ているもの | 個々のデータの「ご近所さん」 | データ全体の「広がり」(分散) |
| データの構造 | 非線形(入り組んだ道)が得意 | 線形(まっすぐな道)が得意 |
| 計算時間 | 長め(特にデータが多いと大変) | 短め |
| 結果の軸の意味 | 特に意味はない(点と点の相対位置が重要) | 意味がある(元の特徴量の組み合わせ) |
| 主な使い道 | データ探索、構造の視覚的理解 | 前処理、他のモデルへの入力 |
使い分けのヒント
- 「手元のデータが、どんなグループに分かれているか目で見てみたい!」→ t-SNE
- 「データの大まかな傾向を知りたい」「機械学習モデルに入れる前に、特徴量の数を減らしたい」→ PCA
- 「t-SNEを使いたいけどデータが多すぎて時間がかかる…」→ 先にPCAで少し次元を減らしてからt-SNEを使う、という合わせ技もアリ!
t-SNEの仕組みって? (難しい数式はナシ!)
「どうやって複雑なデータをきれいな地図に描き直しているの?」 その仕組みを、カレー作りに例えて(?)簡単に説明してみましょう!
- 元の味(高次元)を確認 まず、元のデータの世界で、データ点Aさんとデータ点Bさんがどれくらい「味覚が似ているか(近くにいるか)」を調べます。すごく似ていたら「そっくり度:高」、全然違ったら「そっくり度:低」という感じです。これをすべてのペアで確認します。(実際の計算ではガウス分布というものを使います)
- 新しいお皿(低次元)に仮置き 次に、まっさらな2次元のお皿の上に、データ点をランダムにポイポイっと仮置きします。
- 仮置きの味見 お皿の上でも、AさんとBさんがどれくらい「近くにいるか」を味見します。この時、元の味を確認した時とはちょっと違う味付け(t分布というものを使います。これが名前の「t」の由来!)で味見します。このt分布を使うことで、似ていないデータ同士が適度な距離を保ちやすくなり、後でクラスターがきれいに分かれやすくなる、という工夫がされています。
- 元の味に近づける! 元の味(ステップ1)と、お皿の上の味(ステップ3)を比べます。もし違っていたら、お皿の上のデータ点を少しずつ動かして、元の味に近づくように調整します。これを何度も何度も繰り返します。(この調整の目標が、数学的にはKullback-Leiblerダイバージェンスという指標を小さくすることになります)
これを根気強く繰り返すことで、最終的に元のデータの世界での「ご近所関係」が、2次元のお皿の上でも再現された、きれいな地図が出来上がるというわけです!
Pythonでやってみよう!t-SNE実践コード (scikit-learn)
理屈はなんとなく分かったところで、実際にコードを動かしてみましょう!Pythonの人気ライブラリscikit-learnを使えば、驚くほど簡単にt-SNEを実行できます。
ここでは、先ほどから例に出している手書き数字データセット「MNIST」を使います。
Python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE # t-SNEを使うための道具
from sklearn.datasets import fetch_openml # MNISTデータをダウンロードする道具
from sklearn.decomposition import PCA # PCAと比較するための道具
import time # 時間計測用
print(“MNISTデータの読み込み開始…”)
# MNISTデータの取得 (初回はダウンロードに時間がかかることがあります)
# `parser=’auto’` を指定して、将来のバージョン変更に対応
mnist = fetch_openml(‘mnist_784′, version=1, as_frame=False, parser=’auto’)
# データの前処理
X = mnist.data / 255.0 # ピクセル値を0から1の間に正規化
y = mnist.target.astype(int) # 数字ラベル (0-9)
print(“データ読み込み完了。”)
print(f”元のデータ形状 {X.shape}”) # (70000, 784) -> 7万枚の画像、各784ピクセル
# —– ここから重要!データ量を減らす —–
# 全データ(7万件)でt-SNEを実行すると非常に時間がかかるため、
# ここでは一部のデータ(例 5000件)をランダムに抽出して使います。
n_samples_to_use = 5000
np.random.seed(42) # 毎回同じデータを選ぶために乱数を固定
indices = np.random.permutation(X.shape[0])[:n_samples_to_use] #修正箇所
X_subset = X[indices]
y_subset = y[indices]
print(f”処理対象のサンプル数 {n_samples_to_use}”)
# —– t-SNEの実行 —–
print(“t-SNE計算開始…”)
start_time = time.time()
tsne = TSNE(n_components=2, # 最終的に何次元にするか (2次元グラフなら2)
perplexity=30.0, # ★重要パラメータ!後で説明します (5-50くらいで試す)
learning_rate=’auto’, # 学習のスピード調整 (auto推奨)
n_iter=300, # 計算の反復回数 (最低250は欲しい)
init=’pca’, # 初期配置の方法 (‘pca’か’random’)
random_state=42) # ★毎回同じ結果にするための乱数シード
# fit_transformで次元削減を実行!
X_tsne = tsne.fit_transform(X_subset)
end_time = time.time()
print(f”t-SNE計算終了。所要時間 {end_time – start_time:.2f} 秒”) #修正箇所
# —– PCAも実行して比較 —–
print(“PCA計算開始…”)
start_time = time.time()
pca = PCA(n_components=2, random_state=42)
X_pca = pca.fit_transform(X_subset)
end_time = time.time()
print(f”PCA計算終了。所要時間 {end_time – start_time:.2f} 秒”) # t-SNEよりずっと速いはず!#修正箇所
# —– 結果をグラフで表示 —–
print(“グラフ描画中…”)
plt.figure(figsize=(14, 6)) # 横長の図を用意
# t-SNEの結果をプロット
plt.subplot(1, 2, 1) # 1行2列のグラフの1番目
scatter_tsne = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y_subset, cmap=’tab10′, s=10, alpha=0.8) #修正箇所
plt.title(f’t-SNE (perplexity={tsne.perplexity})’, fontsize=14)
plt.xlabel(‘t-SNE Dimension 1’)
plt.ylabel(‘t-SNE Dimension 2’)
# 凡例(どの色がどの数字か)を表示
handles, labels = scatter_tsne.legend_elements()
plt.legend(handles, np.unique(y_subset).astype(str), title=”Digits”)
# PCAの結果をプロット
plt.subplot(1, 2, 2) # 1行2列のグラフの2番目
scatter_pca = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_subset, cmap=’tab10′, s=10, alpha=0.8) #修正箇所
plt.title(‘PCA’, fontsize=14)
plt.xlabel(‘Principal Component 1’)
plt.ylabel(‘Principal Component 2’)
# 凡例を表示
handles, labels = scatter_pca.legend_elements()
plt.legend(handles, np.unique(y_subset).astype(str), title=”Digits”)
plt.suptitle(‘MNIST Dataset Visualization ({} samples)’.format(n_samples_to_use), fontsize=16)
plt.tight_layout(rect=[0, 0.03, 1, 0.95]) # タイトルが重ならないように調整
plt.show()
print(“グラフ表示完了。”)
コードのポイント解説
- データ量の削減 MNISTデータは7万件ありますが、そのままt-SNEにかけると数分〜数十分かかることもあります。学習や試行錯誤の段階では、このように一部をランダムサンプリング(n_samples_to_useで数を指定)して使うのが現実的です。
- TSNE(…)の中のパラメータ
- n_components=2 2次元のグラフにプロットするので2を指定します。
- perplexity=30.0 ★パープレキシティ。これがt-SNEの「性格」を決める重要なパラメータです。ざっくり言うと「一つの点が、どれくらいの範囲の『ご近所さん』を気にするか」の度合い。低い値(例 5)だと、すごく近い点同士の関係を重視し、細かいクラスターがたくさんできる傾向があります。高い値(例 50)だと、もう少し広い範囲の関係を見て、より大きなクラスターを形成しようとします。どの値が最適かはデータによるので、いくつか試してみるのが基本です。30あたりがよく使われる出発点です。
- learning_rate=’auto’ 計算の調整ステップ幅。’auto’が推奨されています。
- n_iter=300 計算の繰り返し回数。デフォルトは1000ですが、ここでは少し短縮しています。ちゃんと収束させるには250以上、できれば1000回程度が推奨されます。
- init=’pca’ 計算の初期状態をPCAの結果を使うことで、計算が安定したり速くなったりすることがあります。
- random_state=42 ★重要! これを指定しないと、実行するたびに結果のプロットが微妙に変わってしまいます。比較したり、結果を誰かに見せたりする際には、必ず指定しましょう。数字は何でも良いですが、慣習的に42がよく使われます。
- fit_transform(X_subset) この一行で、実際に次元削減の計算が実行され、結果がX_tsneに格納されます。
結果を見てみよう!(MNISTの可視化)
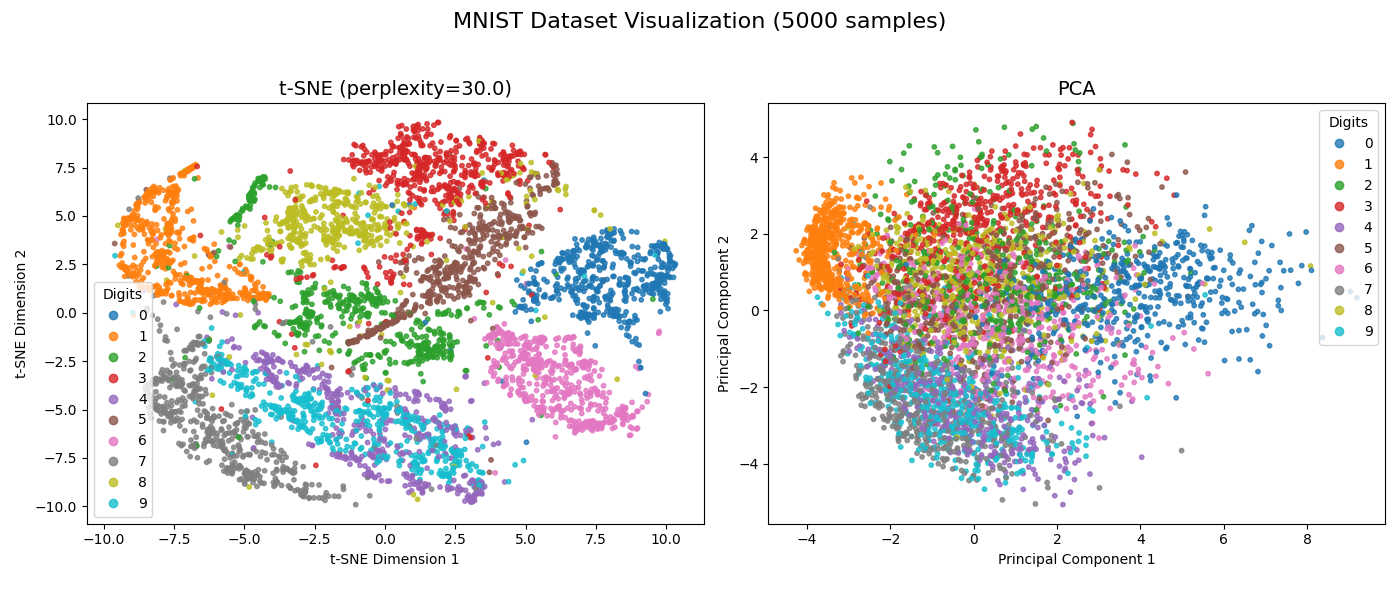
上のコードを実行すると、次のようなグラフが表示されるはずです。(※乱数や環境によって多少見た目は変わります)
MNISTデータの可視化比較: (左) t-SNE、(右) PCA。t-SNEの方が各数字のクラスタがきれいに分離されているのが分かります。
どうでしょうか?右側のPCAの結果と比べると、左側のt-SNEの結果の方が、同じ数字(同じ色)の点がきゅっと集まって、違う数字のグループとくっきり分かれているのが見て取れますね!これが、t-SNEが複雑なデータの構造を捉えるのが得意な証拠です。
パープレキシティを変えるとどうなる?
【強調ポイント!】パープレキシティの値は結果に大きく影響します。 試しに、perplexityの値を例えば5や50に変えて実行してみてください。きっと、クラスターの見え方が変わるはずです。
パープレキシティによるt-SNEの結果の違い(例:左からperplexity=5, 30, 50)。値が小さいと局所的な構造が強調され、大きいとよりまとまったクラスターになりやすい傾向があります。
このように、最適なパープレキシティはデータによって異なるため、いくつか試してみて、一番データの特徴を捉えている(とあなたが解釈できる)結果を選ぶことが大切です。
使う前に知っておきたい注意点!
t-SNEは強力なツールですが、使う上でいくつか知っておくべき注意点があります。
- 計算コストが高い(時間がかかる)【強調ポイント!】データ数や次元数が多くなると、計算に非常に時間がかかります。 数十万件を超えるようなデータには、そのまま適用するのは難しいことが多いです。
- 対策:データをランダムにサンプリングする、先にPCAで次元削減しておく、など。
- グローバルな構造は保証されない t-SNEは「ご近所関係」を保つことを最優先します。そのため、プロット上のクラスター間の距離や、クラスターの大きさ、密度は、必ずしも元のデータの関係性を正確に反映しているとは限りません。
- 「AクラスターとBクラスターがプロット上で近いから、元のデータでも似ているはずだ」と安易に判断するのは危険です!
- 結果の解釈は慎重に 上記の理由から、t-SNEのプロットはあくまで「データ探索の手がかり」と捉えましょう。見えたクラスターが本当に意味のあるグループなのかは、他の分析やドメイン知識(そのデータに関する知識)と照らし合わせて判断する必要があります。
- パラメータ依存性が高い 【強調ポイント!】特にパープレキシティの値によって、結果の見え方が大きく変わります。 試行錯誤が必要です。
- 実行ごとに結果が変わる random_stateを指定しないと、毎回微妙に違う結果になります。再現性が必要な場合は必ず指定しましょう。
- プロットの軸に意味はない t-SNEのグラフのX軸、Y軸には、PCAの主成分のような具体的な意味はありません。重要なのは、点と点の相対的な位置関係です。
一番大事なのは、「t-SNEの見た目だけで結論を出さない」ことです!
どんなことに使えるの? (応用例)
t-SNEはその可視化能力から、様々な分野で使われています。
- 画像データの分類・検索 似たような画像を近くに集めて表示する。
- 自然言語処理 単語や文書の意味的な近さを可視化する。
- 顧客分析 似たような購買パターンを持つ顧客グループを発見する(セグメンテーション)。
- 生物学・医学 細胞の種類を分類したり、遺伝子の発現パターンを可視化したりする。
- 異常検知 正常なデータのかたまりからポツンと離れた点を見つけて、異常なデータ(不正利用など)の候補を見つける。
あなたの持っているデータにも、きっと面白い使い方があるはずです!
まとめ:t-SNEでデータの世界を探検しよう!
今回は、高次元データを分かりやすく「見える化」してくれるt-SNEについて解説しました。
- t-SNEは、高次元データの局所的な近傍関係(ご近所付き合い)を保ちながら、2Dや3Dに可視化する非線形次元削減手法です。
- PCAと比べて、複雑なデータの構造やクラスターを捉えるのが得意です。
- Pythonのscikit-learnを使えば簡単に試せますが、パープレキシティなどのパラメータ調整が重要です。
- 計算コストが高く、クラスター間の距離やサイズの解釈には注意が必要です。
t-SNEは、複雑で取っ付きにくい高次元データの中に隠されたパターンや構造を発見するための、強力な第一歩となります。注意点をしっかり理解した上で使えば、あなたのデータ分析の世界を大きく広げてくれるはずです。
ぜひ、この記事のコードを参考に、あなた自身の手でt-SNEを動かして、データの世界を探検してみてください!
コメント