
「大量の顧客データ、どうやってグループ分けすればいいんだろう?」 「アンケート結果に隠れた、ユーザーの本音を見つけたい…」
データ分析の世界に足を踏み入れたばかりのあなたは、こんな疑問を持っていませんか? そんなとき、強力な味方になってくれるのが「クラスタ分析(クラスター分析)」です。
クラスタ分析は、AI・機械学習の分野、特に「教師なし学習」と呼ばれる領域の基本的な手法の一つ。そして、G検定(ジェネラリスト検定)の合格を目指す上でも、避けては通れない重要なテーマです。
この記事では、G検定の初学者の方でも理解できるよう、クラスタ分析の基本から、
- クラスタ分析って、そもそも何?
- どんな種類があるの?(階層的 vs 非階層的)
- G検定でよく出る代表的な手法(k-means法、ウォード法)
- どんなことに使われているの?(具体例:顧客分析)
- 他の分析手法との違いは?
- 使うときの注意点
などを、図や具体例を交えながら、やさしく・わかりやすく解説していきます。この記事を読めば、クラスタ分析の概要を掴み、G検定対策の第一歩を踏み出せるはずです!
クラスタ分析って、なに? ~仲間探しのお手伝い~
クラスタ分析の基本アイデア
クラスタ分析を一言でいうと、「似たもの同士を集めてグループを作る」ための分析手法です。たくさんのデータの中から、性質が似ているものを自動的に見つけ出し、「クラスター」と呼ばれるグループに分けてくれます。
例えば、スーパーマーケットの商品棚を思い浮かべてください。お菓子コーナー、野菜コーナー、飲み物コーナー…と、似た種類の商品が集められていますよね? あれも、広い意味ではクラスタ分析的な考え方に基づいています。クラスタ分析は、コンピューターを使って、もっと複雑なデータから自動で「仲間探し」をしてくれる、賢いお手伝いさんなのです。
ここで重要なのが、クラスタ分析は「教師なし学習」に分類されるということ。「教師なし」とは、事前に「このデータはこのグループに属する」という正解(ラベル)を与えずに、データそのものの特徴だけを頼りに、コンピューターが自動でパターンや構造を見つけ出す学習方法です。
なぜG検定で重要?
G検定は、AI・ディープラーニングの活用に必要な知識(ジェネラリストとしての知識)を問う試験です。クラスタ分析は、機械学習の基礎であり、特にマーケティング(顧客分析)など、ビジネスへの応用範囲が広いため、G検定のシラバスでも重要な位置を占めています。
- 機械学習の基本を理解するため
- データから知見を得る具体的な手法を知るため
- ビジネス応用(特にマーケティング)のイメージを掴むため
これらの理由から、G検定合格を目指すなら、クラスタ分析の基本はしっかり押さえておく必要があるのです。
クラスタ分析の主な種類:大きく分けて2つ!
クラスタ分析のやり方には、大きく分けて2つのアプローチがあります。「階層的(かいそうてき)クラスタ分析」と「非階層的(ひかいそうてき)クラスタ分析」です。
じわじわ仲間を増やしていく「階層的クラスタ分析」
これは、一番似ているデータ同士から順番にペアを作り、そのペアと次に似ているものを…というように、トーナメント方式のように、少しずつグループを大きくしていく方法です。
最終的に、全てのデータがひとつの大きなグループになるまでの過程が、樹木のような図で示されます。これを「デンドログラム(樹形図)」と呼びます。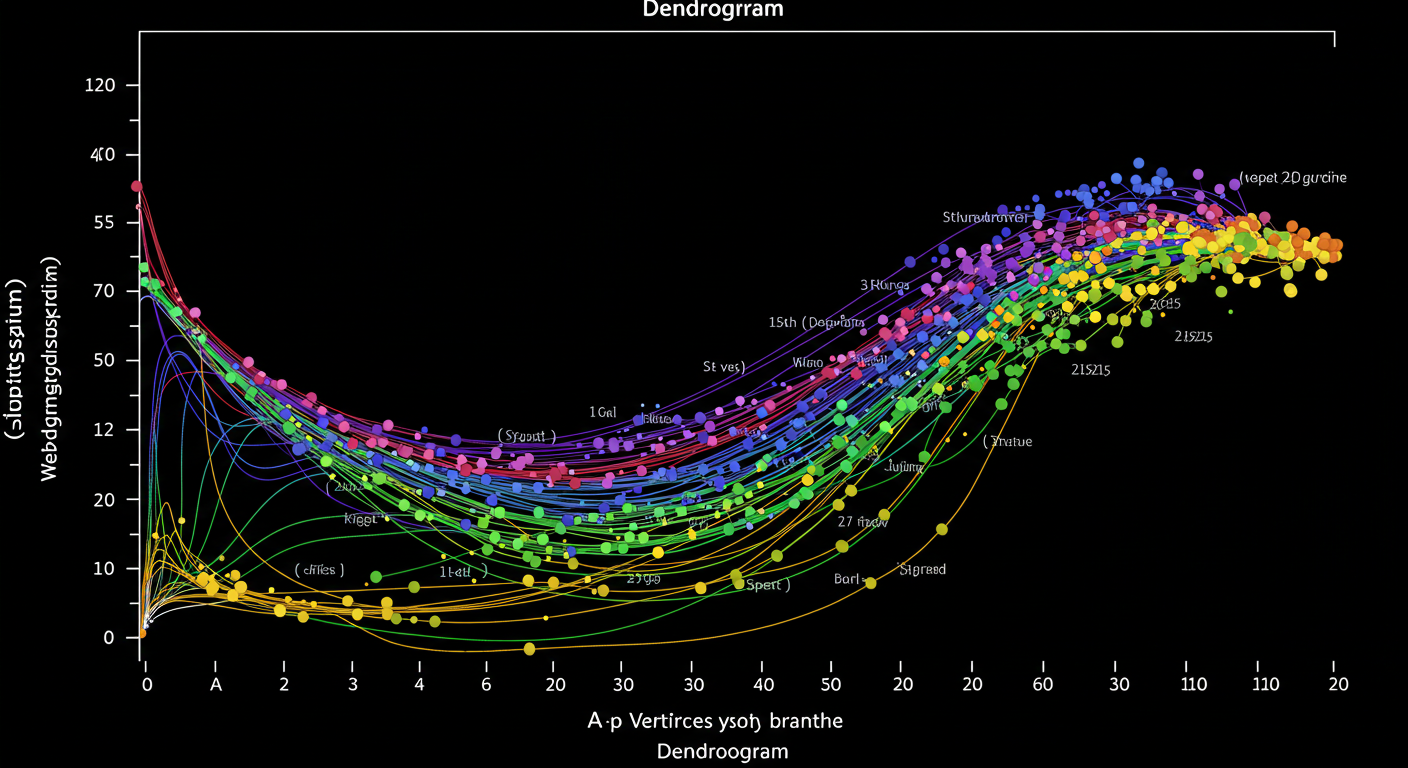
階層的クラスタ分析の特徴
- デンドログラムで結果がわかりやすい どのデータとどのデータが似ているか、グループがどう形成されたかの過程が見える。
- クラスター数を事前に決めなくて良い 分析後にデンドログラムを見て、「この高さで切れば〇個のグループに分かれるな」と判断できる。
- 計算量が多い データが増えると、組み合わせの計算が爆発的に増えるため、比較的小規模なデータの分析に向いている。
代表的な手法として「ウォード法」があります(後ほど詳しく説明します)。
最初からグループ数を決める「非階層的クラスタ分析」
こちらは、最初に「いくつのグループに分けたいか」を決めてから、各データがどのグループに属するのが最も適切かを計算していく方法です。階層的な構造は作りません。
非階層的クラスタ分析の特徴
- 最初にクラスター数を決める必要がある 分析者が「今回は5つのグループに分けよう」などと指定する。
- 計算が比較的速い 階層的な組み合わせを考えないため、大量のデータ(ビッグデータ)でも扱いやすい。
- 大規模データ向き 多くのデータポイントを効率的に分類できる。
代表的な手法として「k-means(ケイミーンズ)法」があります(こちらも後ほど詳しく説明します)。
どう使い分ける? G検定対策のポイント
G検定ポイント 階層的と非階層的、それぞれの特徴と使い分けは頻出です!
| 特徴 | 階層的クラスタ分析 | 非階層的クラスタ分析 |
| クラスター数 | 事前に決めなくて良い(後で決める) | 事前に決める必要がある |
| 結果の可視化 | デンドログラムで過程がわかる | グループ分けの結果のみ |
| 計算量 | 多い(データ量が多いと大変) | 少ない(大規模データ向き) |
| 得意なデータ | 比較的小規模 | 大規模 |
| 代表的な手法 | ウォード法、群平均法、最短距離法など | k-means法 |
- データの量 データが少ないなら階層的、多いなら非階層的が候補になります。
- クラスター数 いくつに分けるか見当がつかない場合は階層的、ある程度決まっているなら非階層的が良いでしょう。
- 過程を見たいか グループができるまでの過程を詳しく見たいなら階層的が適しています。
G検定頻出!代表的なアルゴリズムをチェック
それでは、G検定で特によく問われる代表的なアルゴリズム、「k-means法」と「ウォード法」を見ていきましょう。
k-means法(非階層):シンプルだけどパワフル!
k-means法は、非階層的クラスタ分析の最も代表的な手法です。「k」は、いくつのクラスターに分けるかという「クラスター数」を意味します。
k-means法のざっくりとした流れ
- グループ数kを決める まず、「今回は〇個のグループに分けよう!」と決めます(例:k=3)。
- 仮のグループ中心(セントロイド)を置く データ空間に、k個の「仮の中心点」をランダム(または特定の方法で)に置きます。
- 各データを一番近い中心のグループに入れる すべてのデータ点について、一番近くにある中心点のグループに割り当てます。
- グループの中心を再計算 各グループに所属するデータ点の「平均的な位置」を計算し、そこを新しい中心点とします。
- 中心が動かなくなるまで繰り返す 3と4を繰り返します。グループの割り当てが変わらなくなったり、中心点の移動がごくわずかになったら、完了です。
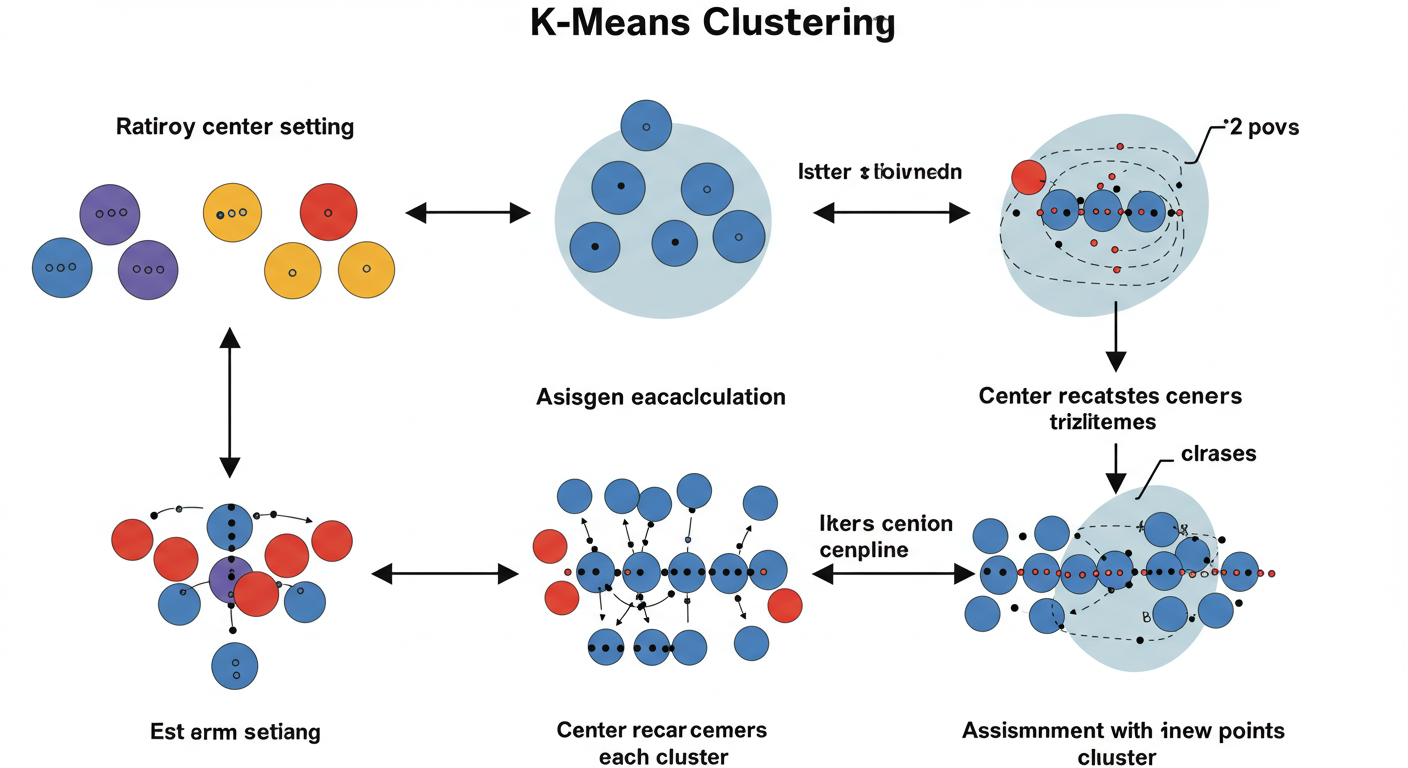
k-means法のメリット・デメリット
- メリット
- アルゴリズムがシンプルで理解しやすい。
- 計算が速く、大規模なデータセットにも適用できる。
- デメリット
- 最初にクラスター数kを自分で決める必要がある。
- 初期の中心点の選び方によって結果が変わることがある(初期値依存性)。
- 外れ値(他のデータから極端に離れた値)の影響を受けやすい。
- 球状(円形)のクラスターを見つけるのは得意だが、複雑な形状のクラスターは苦手。
G検定ポイント k-means法のメリット・デメリット、特に「最初にkを決める必要がある」「初期値依存性がある」「計算が速い」点は重要です。
ウォード法(階層):グループ内のまとまりを重視!
ウォード法は、階層的クラスタ分析でよく使われる手法の一つです。この手法は、グループを合体させていく際に、「グループ内のデータのバラつき(分散)の増加量が最も小さくなる」組み合わせを選んでいきます。つまり、できるだけ中身がギュッとまとまった(均質な)クラスターを作ろうとします。
ウォード法の考え方
たくさんのデータ点の中から、まず最も似ている(距離が近い)2つの点をグループにします。次に、どのグループ(または単独の点)同士を結合すれば、新しくできるグループ内のバラつきの増加が一番少ないかを計算し、その組み合わせを選んで結合…という作業を繰り返し、最終的に一つの大きなグループになるまで続けます。
ウォード法のメリット・デメリット
- メリット
- クラスター数を分析後にデンドログラムを見て決められる。
- 比較的、各クラスターのサイズが均等になりやすく、解釈しやすいきれいなクラスターが形成されやすい傾向がある。
- デメリット
- すべての組み合わせについて計算するため、計算量が非常に多く、大規模なデータには向かない。
- 外れ値の影響はk-meansより受けにくいとされるが、それでも注意は必要。
デンドログラムの見方(再掲) ウォード法の結果はデンドログラムで示されます。この図の「縦軸(高さ)」は、クラスター間の距離(非類似度)や、結合によるクラスター内分散の増加量を表します。どこか適当な高さで横に線を引くと、その線と交わる縦線の数がクラスター数になります。どこで切るかは、分析の目的やデータの性質を考慮して判断します。
G検定ポイント ウォード法は「階層的」であり、「クラスター内分散の増加量を最小にする」という基準で結合すること、「計算量が多い」ことを覚えておきましょう。
G検定対策:k-meansとウォード法の違いを押さえよう!
| 比較項目 | k-means法 | ウォード法 |
| 分析の種類 | 非階層的 | 階層的 |
| クラスター数決定 | 分析前に決定 | 分析後にデンドログラムを見て決定 |
| アルゴリズム | 中心点との距離で所属決定、中心再計算 | クラスター内分散の増加最小で結合 |
| 計算量 | 少ない(大規模データ向き) | 多い(小〜中規模データ向き) |
| 得意な形状 | 球状 | 様々な形状(比較的きれいなクラスター傾向) |
| 初期値依存性 | あり | なし |
| 結果の可視化 | グループ分け結果 | デンドログラム |
この違いをしっかり理解しておくことが、G検定対策の鍵となります!
クラスタ分析、どんなことに使われているの? ~身近な応用例~
クラスタ分析は、机上の空論ではなく、様々なビジネスシーンで実際に活用されています。特にマーケティング分野での応用が有名です。
マーケティングの強力な味方!顧客セグメンテーション(具体例)
企業が持つ顧客データをクラスタ分析にかけることで、顧客をいくつかのグループ(セグメント)に分け、それぞれのグループの特徴に合わせたマーケティング戦略を立てることができます。これを顧客セグメンテーションと言います。
具体例:アパレルECサイトの場合
あるアパレルECサイトが、顧客の購買データ(購入頻度、平均購入金額、よく買う商品カテゴリなど)や顧客属性(年齢、性別、居住地など)を使ってクラスタ分析を行ったとします。その結果、例えば以下のような顧客グループが見えてくるかもしれません。
- 【グループA】高頻度・高単価ロイヤル顧客層
- 特徴:月に何度も購入し、購入単価も高い。新商品や限定品への関心が高い。
- アプローチ:限定クーポンの配布、新商品の先行案内、特別イベントへの招待など、優良顧客向けの施策。
- 【グループB】セール時まとめ買い層
- 特徴:購入頻度は低いが、セール時期にまとめて購入する傾向。価格に敏感。
- アプローチ:セール情報の積極的な告知、まとめ買い割引の提案など。
- 【グループC】特定カテゴリこだわり層
- 特徴:購入する商品カテゴリが偏っている(例:スニーカーばかり買う、特定ブランドが好きなど)。
- アプローチ:関連性の高いカテゴリの新商品情報や特集コンテンツの配信。
- 【グループD】低関与・休眠予備軍
- 特徴:購入頻度・金額ともに低い。サイト訪問も少ない。
- アプローチ:掘り出し物セールの案内、サイト訪問を促すポイント付与キャンペーン、興味を引くコンテンツの提供など、再活性化策。
このように、顧客を理解しやすいグループに分けることで、画一的なアプローチではなく、各グループの心に響くような効果的なマーケティングが可能になります。
その他にもいろいろ!
- 商品・サービスのポジショニング 市場にある商品やサービスを、顧客の評価や特徴に基づいて分類し、自社商品の立ち位置を確認したり、新商品の開発ヒントを得たりします。
- アンケート結果の分析 大量のアンケート回答者を、回答パターンの類似性からグループ分けし、異なる意見を持つ層やニーズを明らかにします。
- 画像データの領域分割(画像セグメンテーション) 画像の中で、色が似ている部分や質感が似ている部分をグループ化する技術にも応用されています(物体認識などの基礎技術)。
他の分析手法との違いも知っておこう(G検定対策)
G検定では、クラスタ分析と他の教師なし学習手法との違いも問われることがあります。代表的なものとの違いを簡単に押さえておきましょう。
主成分分析(PCA)との違い:情報をまとめる vs グループ分け
主成分分析(PCA)は、たくさんの変数(データ項目)がある場合に、それらの情報をできるだけ失わずに、より少ない新しい指標(主成分)に要約する手法です。次元削減とも呼ばれます。 クラスタ分析は、データやサンプルそのものをグループ分けする手法です。 目的が「情報を要約する」のか「グループを作る」のかが大きな違いです。
因子分析との違い:共通の背景を探る vs 似たもの集め
因子分析は、観測された多くの変数の背後にある、直接観測できない共通の要因(因子)を探り出す手法です。例えば、アンケートの様々な質問項目への回答から、「価格重視度」「品質重視度」といった潜在的な因子を見つけ出そうとします。 クラスタ分析は、あくまでデータ同士の類似性に基づいてグループ化します。 目的が「背後にある共通要因を探る」のか「似たものを集める」のかが異なります。
G検定ポイント それぞれの手法が「何を目的としているか」を区別できるようにしておきましょう。
クラスタ分析を使う上での注意点
クラスタ分析は便利な手法ですが、使う上でいくつか知っておくべき注意点があります。
- 「絶対的な正解」はない
教師なし学習なので、どう分けるのが唯一正しいという答えはありません。分析目的や結果の解釈しやすさから、適切なグループ分けを判断する必要があります。
- どの変数を使うかで結果が変わる
分析にどのデータ項目(変数)を含めるかによって、グループ分けの結果は大きく変わります。目的 Tに合わせて適切な変数を選ぶことが重要です。
- 非階層的手法ではkの数が重要
k-means法などでは、最初に決めるクラスター数kが結果に大きく影響します。適切なkを見つけるための補助的な手法(エルボー法など)もありますが、最終的には分析者が判断します。
- 結果の解釈が重要
分析結果のクラスターが統計的に意味があるだけでなく、ビジネス上などの実用的な意味を持つか解釈することが大切です。
まとめ:クラスタ分析の第一歩を踏み出そう!
今回は、教師なし学習の代表的な手法である「クラスタ分析」について、G検定初学者向けに基本から解説しました。
- クラスタ分析は「似たもの同士を集めてグループ分け」する手法。
- 「階層的(デンドログラム、ウォード法など)」と「非階層的(k-means法など)」の2種類がある。
- G検定では、k-means法とウォード法の違いや特徴、他の手法との比較がポイント。
- 顧客セグメンテーションなど、ビジネスで広く活用されている。
- 使う際には、変数の選択や結果の解釈に注意が必要。
クラスタ分析は、データの中に隠れたパターンや構造を見つけ出し、ビジネスや研究に役立つ洞察を与えてくれる強力なツールです。G検定の学習を通じて、ぜひその基本をマスターしてください。
読者への問いかけ・エンゲージメント
クラスタ分析、少し身近に感じられましたか? データをグループ分けする、という考え方は、意外と私たちの身の回りでも使われていますよね。
G検定の勉強は覚えることが多くて大変かもしれませんが、一つ一つの手法が「何のために」「どんな仕組みで」使われるのかを理解していくと、きっと面白くなってくるはずです。一緒に頑張りましょう!
この記事を読んでみて、分かりにくかった点や、もっと知りたいクラスタリング手法、あるいは他の分析手法についてなど、何かあればぜひ下のコメント欄で教えてください!
コメント