
「手元に大量のデータがあるけど、どこから見ればいいんだろう?」 「AIって賢いけど、どうやってデータの特徴を見つけているの?」
データサイエンスを学び始めると、こんな疑問を持つことはありませんか?
実は、これらの疑問を解決する強力な「魔法の杖」があります。それが今回ご紹介する特異値分解(Singular Value Decomposition、SVD)です!
SVDは、一見複雑に見えるデータを、その本質を示すシンプルな要素に分解してくれる驚きの技術。機械学習、特に教師なし学習の世界ではなくてはならない存在であり、画像処理や推薦システムなど、私たちの身の回りの多くの技術を支えています。
この記事を読めば、あなたも以下のことができるようになります!
- SVDが何なのか、基本的な仕組みを理解できる
- SVDがデータをどのように「分解」するのかイメージできる
- SVDがどんな場面で活躍しているか(次元削減、推薦システムなど)を知れる
- SVDを使うメリット・デメリットがわかる
数式は最小限にして、図や具体例を交えながら分かりやすく解説していきますので、線形代数に少し苦手意識がある方でも大丈夫です。さあ、一緒にSVDの世界を探検しましょう!
特異値分解(SVD)って、一体何者?
難しい数式は一旦忘れてOK!SVDのキホン
SVDって、なんだか難しそうな名前ですよね。でも、基本的な考え方はシンプルです。
SVDを一言でいうと、「どんなデータ(行列)も、3つのシンプルな要素(行列)に分解する技術」です。
まるで、一枚の複雑な写真を、「被写体の向き」「写っているものの重要度」「背景のパターン」といった要素に分解するようなイメージです。SVDを使うことで、元のデータが持つ構造や本質的な情報を、より分かりやすい形で取り出すことができるのです。
SVDの仕組み:M=UΣVT を見てみよう
SVDでは、元のデータを行列 M としたとき、それを以下の3つの行列の積に分解します。
M=UΣVT
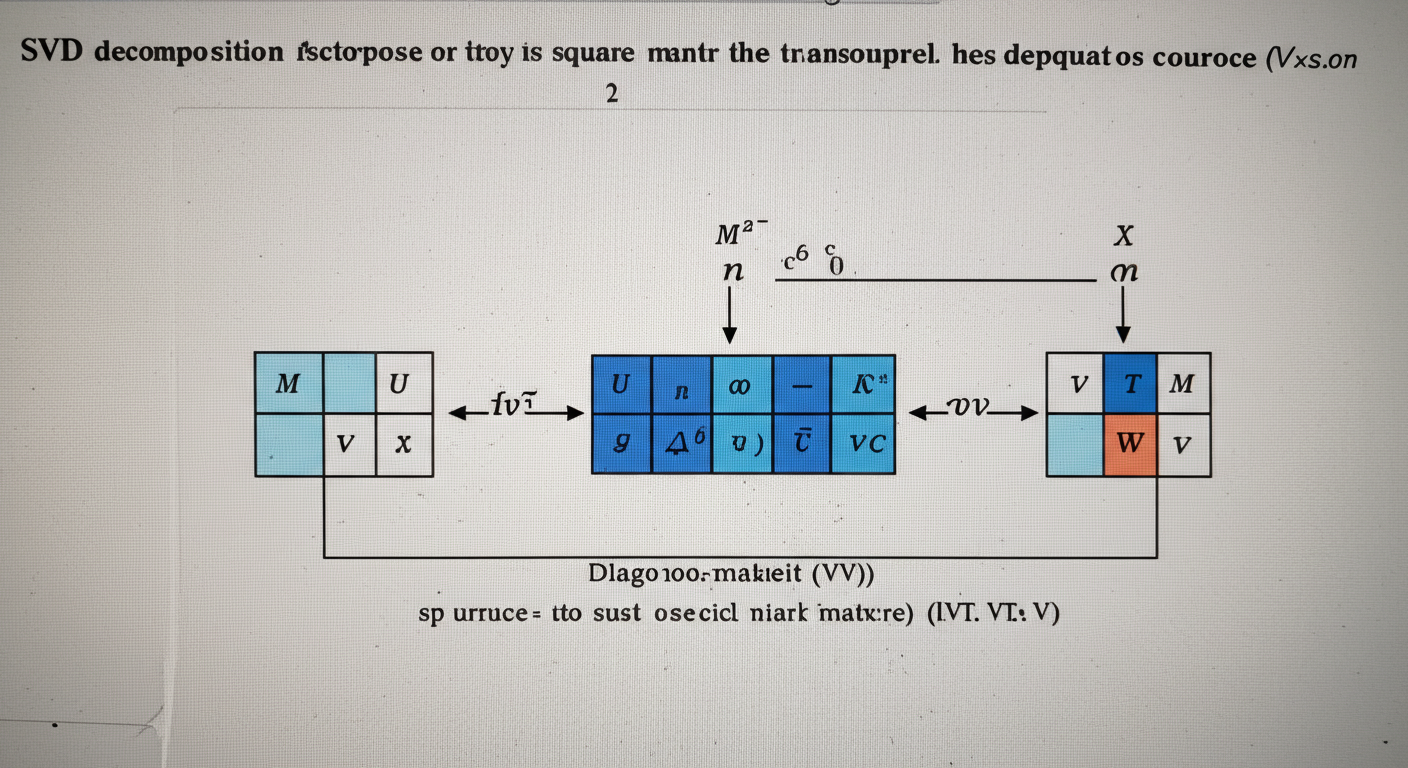
それぞれの行列には、ちゃんと意味があります。
- U (ユー):左特異ベクトル
- 元のデータの「特徴の方向」を表す行列です。データの主要な変動がどの方向にあるかを示します。列ベクトルは互いに直交(=独立した方向)しています。
- Σ (シグマ):特異値行列
- それぞれの特徴の方向がどれだけ「重要か」を示す値(特異値)が、対角線上に大きい順に並んだ行列です。特異値が大きいほど、その方向がデータ全体を表す上で重要であることを意味します。他の成分はすべて0です。
- VT (ブイの転置):右特異ベクトル
- 元のデータの「特徴のパターン」を表す行列 V の転置(行と列を入れ替えたもの)です。こちらも行ベクトル(元のVでは列ベクトル)が互いに直交しています。
ここがSVDのすごいポイント! SVDは、どんな形(縦長、横長、正方形)の行列 M でも、必ずこの3つの行列に分解できるんです!これは、正方行列しか扱えない固有値分解などと比べても、非常に強力な点であり、SVDが様々なデータ分析で活躍する理由の一つです。
なぜSVDがすごい?データを見る目が変わる!
データの「本質」を見抜く力
SVDの最大の魅力は、データの「本質」を見抜く力にあります。
先ほど説明した特異値行列 Σ には、データの特徴の「重要度」を示す特異値が、大きい順に並んでいましたね。実は、多くの場合、少数の大きな特異値に対応する部分だけで、元のデータの情報のほとんどを表現できるのです!
逆に言えば、小さな特異値に対応する部分は、データの細かい部分やノイズ(あまり重要でない情報)を表していることが多いと考えられます。
つまり、SVDを使って大きな特異値とその対応するベクトルだけを残し、小さな特異値の部分を「切り捨てる」ことで、データの本質的な情報を保ったまま、ノイズを除去したり、データ量を削減したりできるのです。
幾何学的なイメージ:データの形を変える魔法
少しだけ数学的な話をすると、SVDはデータを幾何学的に「変形」させる操作として捉えることもできます。
元のデータを点の集まりだと考えてみてください。SVDによる変換 (M=UΣVT) は、以下の3ステップの操作に対応します。
- VT による回転(または反転) データの向きを変えます。
- Σ による伸縮 各軸方向にデータを伸ばしたり縮めたりします。特異値が大きい軸ほど、大きく伸びます。
- U による回転(または反転) 最後にデータの向きをもう一度変えます。
この「伸縮」の度合い(特異値)が大きい方向が、データが最も広がっている方向、つまりデータにとって最も重要な特徴を表す方向と考えることができます。SVDは、このようにデータの構造を幾何学的に捉え、重要な方向を見つけ出すことができるのです。
SVDはどこで活躍してる?驚きの応用例!
SVDがデータの「本質」を見抜く力を持っていることは分かりましたね。では、実際にどのような場面でその力が活かされているのでしょうか?驚くほど広い分野で活躍しているSVDの応用例を見ていきましょう!
教師なし学習のスーパーヒーロー
教師なし学習とは、データに正解ラベルが与えられていない状態で、データ自身が持つ構造やパターンを見つけ出す手法です。SVDは、この教師なし学習において非常に重要な役割を果たします。
- 次元削減:情報を保ったままデータをコンパクトに!
- たくさんの特徴量(データの列)を持つ高次元データを、より少ない特徴量を持つ低次元データに変換する技術です。
- SVDを使って重要度の高い特異値とベクトルだけを残すことで、データの本質的な情報を失わずに次元を削減できます。

- メリット 計算が速くなる、データを扱いやすくなる、ノイズが減って分析しやすくなる。
- 例 大量のアンケート項目から、回答者の主要な意見の傾向(例:「価格重視派」「品質重視派」など)を少ない指標で表現する。
- 特徴抽出:データに隠された「個性」を見つける!
- 元の特徴量を組み合わせることで、データの本質をよりよく表す新しい特徴量を作り出すことです。SVDで得られる特異ベクトルは、まさにこの新しい特徴量と考えることができます。
- 例 顧客の購買履歴データ(どの商品をいつ買ったかなど)にSVDを適用し、「節約志向」「トレンドに敏感」「特定ブランド好き」といった顧客の潜在的な特徴(個性)を抽出する。
- 主成分分析(PCA)との関係:実は裏で支えてる!
- 次元削減の代表的な手法である主成分分析(PCA)は、実はSVDを使って効率的に計算することができます。SVDはPCAの強力な計算エンジンでもあるのです。(ここでは詳細には触れませんが、興味のある方は調べてみてください!)
- 協調フィルタリング (推薦システム):あなたへのおすすめはこうして作られる!
- Amazonのおすすめ商品や、Netflixのおすすめ映画など、多くの推薦システムでSVDが活躍しています。
- 「ユーザーがどのアイテムをどう評価したか」という表(行列)にSVDを適用します。すると、ユーザーの「潜在的な好み」とアイテムの「潜在的な特徴」が抽出できます。
- これにより、ユーザーがまだ評価していないアイテムの中から、そのユーザーが好きそうなものを予測して推薦することができるのです。
- トピックモデル (LSA):文章に隠されたテーマを発見!
- 大量の文書データから、その背景にある主要な「トピック」を自動で見つけ出す技術(潜在意味解析、LSA)にもSVDが使われています。
- 「どの文書にどの単語がどれくらい出現するか」という行列にSVDを適用することで、単語とトピック、文書とトピックの関連性を分析できます。
- 例 大量のニュース記事をSVDで分析し、「経済」「政治」「スポーツ」「テクノロジー」といった隠れたトピックを発見し、記事を自動的に分類する。
データ分析の世界を広げる多彩な応用
SVDの活躍の場は、教師なし学習だけにとどまりません。
- データ圧縮:画像や音声データを軽くする!
- SVDを使って重要度の低い情報を少し削ることで、見た目や音質を大きく損なわずにデータサイズを小さくできます。JPEG圧縮などにも関連する考え方です。
- 例 Webサイトの画像データを圧縮して、ページの表示速度を改善する。
- 画像処理:ノイズ除去できれいな画像に!
- 画像データにSVDを適用し、ノイズに対応するであろう小さな特異値の部分を取り除くことで、画像をきれいにすることができます。
- 自然言語処理:文書検索の精度アップ!
- 文書中の単語の意味的な関連性を捉えることで、より賢い文書検索や文書分類を実現します。
- その他:擬似逆行列の計算など
- 数学的には、逆行列を持たない行列に対しても「それに近いもの(擬似逆行列)」を計算でき、方程式の解を求めるときなどに役立ちます。(少し専門的な話なので、ここでは紹介にとどめます。)
このように、SVDはデータ分析から画像処理、自然言語処理、推薦システムまで、本当に幅広い分野で基礎技術として活躍しているのです!
SVDを使うメリットと、ちょっとした注意点
これだけ多くの場面で活躍するSVDですが、使う上で知っておきたい良い点(メリット)と、少し気をつけるべき点(デメリット)を整理しておきましょう。
SVDのすごいところ(メリット)
- どんな行列にも使える「万能性」 データの形(行数と列数)を選ばずに、どんな行列でも分解できるのは最大の強みです。
- 計算が比較的安定している「信頼性」 数値計算の誤差が出にくく、安定して結果を得やすいアルゴリズムです。
- データの重要な部分が分かる「洞察力」 特異値の大きさを見ることで、データのどこに重要な情報が隠れているかを知る手がかりになります。次元削減や特徴抽出の強力な根拠となります。
ここは注意!(デメリット)
- データが大きいと計算に時間がかかることがある 行列のサイズが非常に大きい場合、全ての要素を正確に計算(完全なSVD)しようとすると、計算時間や必要なメモリが多くなることがあります。(ただし、近似的な計算手法も多く開発されています)
- 分解された要素の意味が直感的に分かりにくい場合がある SVDで得られた特異ベクトル(UやVの列/行ベクトル)は、元のデータの様々な特徴が組み合わさったものであるため、それが具体的に「何を意味するのか」を解釈するのが難しいケースもあります。
とはいえ、これらのデメリットを補って余りあるメリットがあるため、SVDはデータ分析の世界で広く使われ続けています。
【おまけ】PythonでSVDを体験してみよう
理論だけでなく、実際にSVDがどのように計算されるか見てみましょう。ここでは、Pythonの数値計算ライブラリNumPyを使って、簡単な行列をSVDで分解してみます。
Python
import numpy as np
# 簡単な行列を作成
A = np.array([[1, 2, 3],
[4, 5, 6]])
print(“元の行列 A”)
print(A)
# SVDを実行
U, s, VT = np.linalg.svd(A)
# 結果を表示
print(“\n左特異ベクトル U”)
print(U)
print(“\n特異値 s (Σの対角成分)”)
print(s) # NumPyでは特異値は1次元配列で返される
# 特異値を行列Σの形にする (おまけ)
Sigma = np.zeros(A.shape)
Sigma[A.shape, A.shape] = np.diag(s) # 行列のサイズに合わせて対角行列を作成
# 正確には min(A.shape, A.shape) が特異値の数
print(“\n特異値行列 Σ ( reconstructed )”)
print(Sigma) # 表示用。実際の計算ではsを使うことが多い
print(“\n右特異ベクトル V の転置 VT”)
print(VT)
# 分解された行列を掛け合わせて元の行列に戻るか確認
A_reconstructed = U @ Sigma @ VT # ‘@’ はPython 3.5以降の行列積演算子
print(“\n再構成された行列 A_reconstructed”)
print(A_reconstructed)
print(“\n元の行列とほぼ同じになっているか?”, np.allclose(A, A_reconstructed))
このコードを実行すると、元の行列 A が U, s (特異値の配列), VT に分解され、それらを掛け合わせると元の行列に(ほぼ)戻ることが確認できます。
コードの簡単な解説
- import numpy as np NumPyライブラリを使えるようにします。
- A = np.array(…) 行列 A を定義します。
- U, s, VT = np.linalg.svd(A) ここがSVDを実行している部分です。np.linalgモジュールのsvd関数を使います。返り値は U、特異値の1次元配列 s、そして VT です。
- np.diag(s) 特異値の配列 s を対角行列にします。
- U @ Sigma @ VT 分解された3つの行列を掛け合わせて、元の行列を再構成します。
- np.allclose(A, A_reconstructed) 再構成された行列が元の行列と数値的にほぼ等しいかを確認します。
ぜひ、お手元のPython環境でこのコードをコピー&ペーストして実行してみてください!実際に動かしてみることで、SVDがより身近に感じられるはずです。
まとめ:SVDはデータ理解を深める強力な武器!
今回は、データ分析の強力なツールである特異値分解(SVD)について、その基本的な仕組みから、次元削減、特徴抽出、推薦システムといった驚くほど広い応用例、そしてメリット・デメリットまで解説してきました。
SVDを一言でまとめると、「どんなデータ(行列)も、その本質を表す『方向(U)』、『重要度(Σ)』、『パターン(VT)』という3つの要素に分解する魔法の杖」と言えるでしょう。
この魔法の杖を使うことで、私たちは複雑なデータの中に隠された構造を見つけ出し、ノイズに惑わされずに本質的な情報を抽出し、そして機械学習モデルの性能を高めることができます。
データサイエンスや機械学習を学ぶ上で、SVDの考え方を理解しておくことは、あなたのデータを見る目を格段にレベルアップさせてくれるはずです。
この記事が、あなたのSVDへの理解を深める一助となれば幸いです。ぜひ、SVDの知識を活かして、データ分析の世界をもっと楽しんでください!
コメント