
「どの選択肢を選ぶのがベストなんだろう…?」
私たちは日々、多くの選択に迫られています。レストラン選びから、仕事での戦略決定、Webサイトのデザインまで、限られた情報の中で最善手を見つけ出すのは難しい問題ですよね。
特に、AIが自律的に学習を進める強化学習の世界では、「新しい選択肢を試して情報を集めるべきか(探索)」、それとも「今一番良いとわかっている選択肢を選ぶべきか(利用)」というジレンマが常に存在します。これを「探索と利用のトレードオフ」と呼びます。
この重要な課題に対する強力な解決策の一つが、今回ご紹介するUCB (Upper Confidence Bound) 方策です。UCB方策は、「まだよくわからない選択肢は、もしかしたらすごく良いかもしれない!」という楽観的な考え方に基づいて、効率的に最適な選択肢を見つけ出すことを目指します。
この記事を読めば、以下のことがわかります。
- なぜ探索と利用のバランスが重要なのか(多腕バンディット問題)
- UCB方策がどのように意思決定を行うのか(核心的な考え方と計算式)
- 代表的な探索戦略であるε-greedyとの違い
- UCB方策のメリット・デメリット、そして具体的な応用例
- UCB方策の簡単なアルゴリズム(擬似コード付き)
強化学習の基本を学びたい方、データに基づいてより良い意思決定をしたいと考えているエンジニアの方にとって、きっと役立つ内容になるはずです。それでは、一緒にUCB方策の世界を探求していきましょう!
なぜUCB方策が必要? – 探索と利用のジレンマ
UCB方策の必要性を理解するために、まずは強化学習における古典的な問題設定である「多腕バンディット問題」から見ていきましょう。
多腕バンディット問題とは?
想像してみてください。あなたの目の前に、複数のスロットマシン(「バンディットアーム」とも呼ばれます)が並んでいます。それぞれのアームは、引くと異なる確率で当たり(報酬)が出ますが、その確率をあなたは知りません。あなたの目的は、限られた回数だけアームを引ける中で、得られる報酬の合計を最大化することです。

これが多腕バンディット問題の基本的な考え方です。この問題設定は、実は私たちの身の回りの多くの状況に応用できます。
- Webサイト最適化: 複数の広告デザインやボタン配置のうち、どれが最もクリック率が高いか?
- 推薦システム: ユーザーにどの商品や記事を推薦すれば、最も興味を持ってもらえるか?
- 臨床試験: 複数の新薬候補のうち、どれが最も効果的な治療法か?
これらの問題に共通するのは、「複数の選択肢の中から、結果が不確実な状況で、繰り返し選択を行い、最終的な成果(報酬)を最大化したい」という点です。
探索(Exploration) vs 利用(Exploitation)
さて、バンディット問題で報酬を最大化するにはどうすればよいでしょうか?ここで登場するのが「探索と利用のトレードオフ」です。
- 探索 (Exploration): まだあまり試していないアーム(選択肢)を積極的に引いてみて、その当たり確率(良さ)に関する情報を集めることです。「もしかしたら、まだ試していないあのアームが大当たりかもしれない!」という考えに基づきます。
- 利用 (Exploitation): これまでの経験から、現時点で最も当たりやすい(最も良い結果をもたらす)と推定されるアーム(選択肢)を集中的に引くことです。「今一番良さそうなこのアームを引き続けよう」という考えに基づきます。
この二つは、どちらか一方だけではうまくいきません。
- 探索ばかりしていると… 新しい情報を得ることに時間を使いすぎて、既に見つけている良い選択肢を十分に活用できず、トータルの報酬が伸び悩みます。
- 利用ばかりしていると… たまたま最初に見つけたそこそこの選択肢に固執してしまい、実はもっと良い選択肢が存在する可能性を見逃してしまいます。
つまり、長期的に見て最大の報酬を得るためには、探索と利用のバランスをうまく取ることが非常に重要なのです。このバランスを賢く取るための戦略が、UCB方策の核心となります。
UCB方策の核心 – 不確実な選択肢に楽観的になる
探索と利用のバランスを取るために、UCB方策は非常に興味深いアプローチを採用します。それは「不確かさに対する楽観主義 (Optimism in the Face of Uncertainty)」です。
UCB (Upper Confidence Bound) とは?
UCBは、各選択肢(アーム)の「潜在的な価値の上限」を見積もり、その上限値が最も高いものを選択する戦略です。平たく言うと、
「まだよく試していなくて、どれくらい良いかハッキリしない選択肢については、『もしかしたらすごく良いかもしれない!』と楽観的に考えて、積極的に試してみよう!」
という考え方に基づいています。この「楽観的な見積もり」をUCB値と呼びます。
UCB値の計算方法
では、具体的にUCB値はどのように計算されるのでしょうか? UCB値は、主に以下の二つの要素から構成されます。
- これまでの平均報酬 (推定値): その選択肢が過去にどれくらいの報酬をもたらしたか。(利用の側面)
- 不確かさボーナス (信頼上限): その選択肢を試した回数が少ないほど大きくなるボーナス。試行回数が少ない=情報が不確か=まだ高いポテンシャルを秘めているかもしれない、と考えます。(探索の側面)
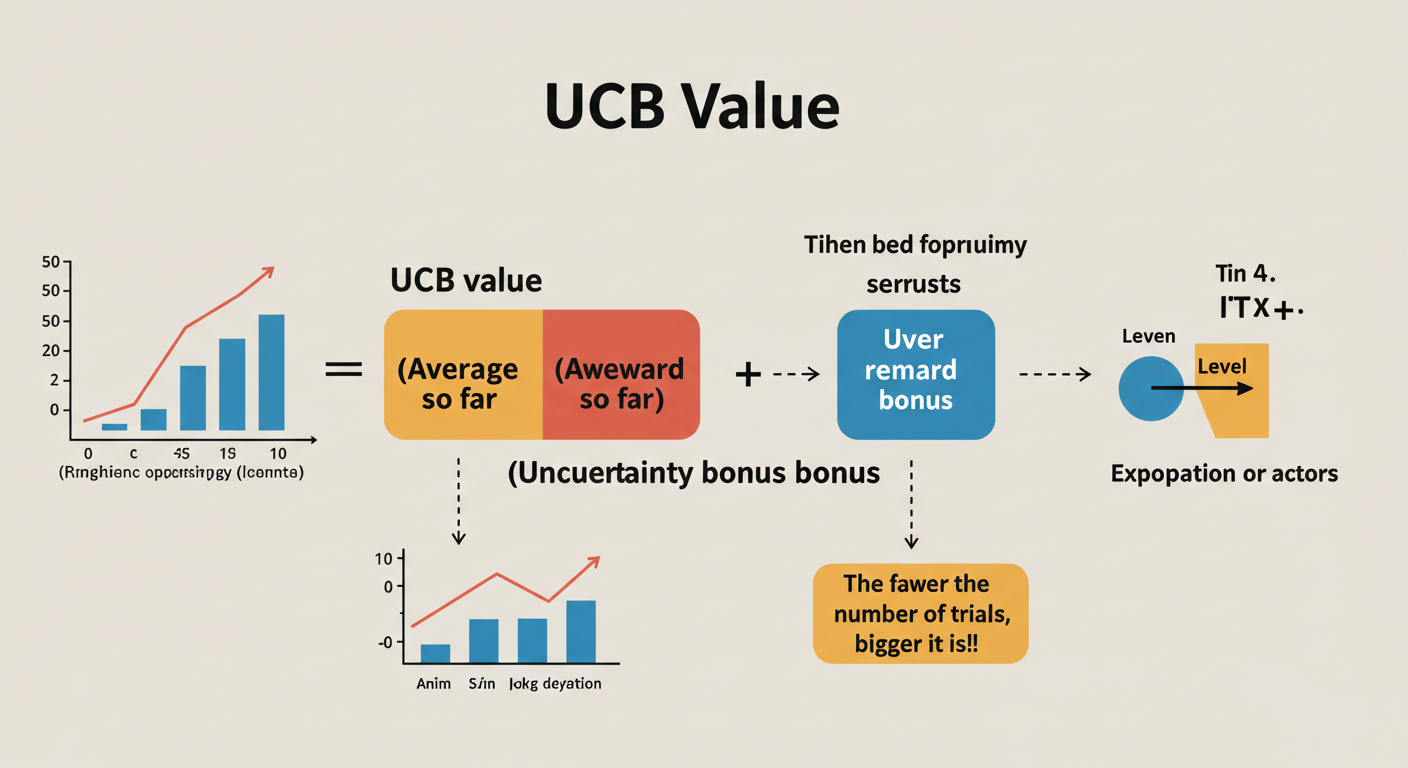
これを数式で表すと、最も基本的なUCB1アルゴリズムでは以下のようになります。
時刻 t における行動 a のUCB値は:
UCBt(a)=Q^t(a)+cNt(a)lnt
各記号の意味は以下の通りです。
- Q^t(a): 時刻 t における行動 a の推定平均報酬(これまでの報酬の平均値)。
- Nt(a): 時刻 t までに行動 a が選択された回数。
- t: 現在までの総ステップ(全アームの試行回数の合計)。
- lnt: t の自然対数。ステップ数が増えるほどゆっくり増加します。
- c: 探索の度合いを調整する正の定数(ハイパーパラメータ)。c が大きいほど、不確かさボーナスの影響が大きくなり、探索をより重視します。(c=2 がよく使われます)
この式のポイントは、右側の「不確かさボーナス」の項です。
- 分母の Nt(a) (行動 a の試行回数) が小さいほど、この項は大きくなります。つまり、まだあまり試されていない行動ほど、大きなボーナスが加算され、UCB値が高くなり、選択されやすくなります。
- 分子の lnt (総ステップ数の対数) があるため、時間が経つにつれて全体的にボーナスは増加しますが、Nt(a) が増えれば、その行動のボーナスは減少していきます。
これにより、アルゴリズムは最初は広く探索し、データが集まるにつれて徐々に有望な行動の利用へとシフトしていくのです。
UCBアルゴリズムの動作ステップ(擬似コード付き)
UCB方策が実際にどのように動くのか、簡単なアルゴリズムのステップと擬似コードで見てみましょう。
UCB1アルゴリズムの擬似コード:
import math
def find_minimum_cost(num_islands, edges):
“””
すべての島を連結にするための最小コストを求める。
Args:
num_islands: 島の数
edges: 橋の情報のリスト。各要素は (島1, 島2, コスト) のタプル
Returns:
最小コスト
“””
# 親ノードを管理する配列(初期値は自分自身)
parent = list(range(num_islands + 1))
# ランク(木の高さ)を管理する配列(初期値は0)
rank = [0] * (num_islands + 1)
def find(i):
“””
ノードiの親(根)を再帰的に見つける。
“””
if parent[i] == i:
return i
parent[i] = find(parent[i]) # 経路圧縮
return parent[i]
def union(i, j):
“””
ノードiとノードjが属する集合を併合する。
“””
root_i = find(i)
root_j = find(j)
if root_i != root_j:
if rank[root_i] < rank[root_j]:
parent[root_i] = root_j
elif rank[root_i] > rank[root_j]:
parent[root_j] = root_i
else:
parent[root_j] = root_i
rank[root_i] += 1
return True
return False
# 橋をコストでソート
edges.sort(key=lambda x: x[2])
minimum_cost = 0
num_edges = 0
for u, v, cost in edges:
if union(u, v):
minimum_cost += cost
num_edges += 1
if num_edges == num_islands – 1:
break
return minimum_cost
# — 初期化 —
# K: アーム(行動)の数
# c: 探索パラメータ (例: sqrt(2))
# 各アームを1回ずつ試す
def solve_ucb(K, c, initial_reward, play_arm, max_steps):
“””
UCBアルゴリズムで多腕バンディット問題を解く。
Args:
K: アームの数
c: 探索パラメータ
initial_reward: アームの初期報酬を返す関数 (例: lambda a: 0.0)
play_arm: アームをプレイして報酬を返す関数 (例: lambda a: np.random.normal(means[a], 1))
max_steps: 最大ステップ数
Returns:
total_reward: 獲得した総報酬
selected_arms: 各ステップで選択したアームのリスト
“””
N = [1] * K # 各アームの試行回数 (最初は全て1)
Q = [initial_reward(a) for a in range(K)] # 各アームの初期報酬推定値
t = K # 総ステップ数
total_reward = 0
selected_arms = []
# — メインループ —
while t < max_steps: # (または指定された回数まで)
t += 1
ucb_values = []
for a in range(K):
if N[a] == 0: # まだ試していないアームがあれば優先 (通常は初期化で回避)
ucb_value = float(‘inf’) # 無限大として最優先
else:
bonus = c * math.sqrt(math.log(t) / N[a])
ucb_value = Q[a] + bonus
ucb_values.append(ucb_value)
# UCB値が最大の行動を選択
selected_arm = ucb_values.index(max(ucb_values)) # ucb_valuesが最大のインデックスを取得
selected_arms.append(selected_arm)
# 選択したアームを実行し、報酬を観測
reward = play_arm(selected_arm)
total_reward += reward
# 選択したアームの情報を更新
# Q(a)の更新 (増分更新): Q_new = Q_old + (reward – Q_old) / N_new
Q[selected_arm] = Q[selected_arm] + (reward – Q[selected_arm]) / N[selected_arm]
N[selected_arm] += 1
return total_reward, selected_arms
# — ユーティリティ関数 —
def argmax(values):
“””値のリストの中で最大値を持つインデックスを返す”””
return values.index(max(values))
# — テスト用関数 —
import numpy as np
def test_ucb():
# テスト用の設定
K = 5 # アームの数
c = math.sqrt(2) # 探索パラメータ
means = [0.1, 0.2, 0.3, 0.4, 0.5] # 各アームの平均報酬
max_steps = 1000
# 初期報酬を0とする関数
initial_reward = lambda a: 0.0
# アームをプレイして報酬を返す関数
def play_arm(a):
return np.random.normal(means[a], 1)
# UCBアルゴリズムを実行
total_reward, selected_arms = solve_ucb(K, c, initial_reward, play_arm, max_steps)
print(f”Total reward: {total_reward}”)
print(f”Selected arms: {selected_arms}”)
if __name__ == “__main__”:
# テスト用UCB実行
test_ucb()
# 入力
n, m = map(int, input().split())
edges = []
for _ in range(m):
u, v, cost = map(int, input().split())
edges.append((u, v, cost))
# 最小コストを計算して出力
print(find_minimum_cost(n, edges))
簡単な解説:
- 初期化: まず、すべてのアームを1回ずつ試して、試行回数と初期の報酬推定値を記録します。
- ループ開始:
- 総ステップ数 t を増やします。
- すべてのアームについて、現在の推定報酬 Q^t(a) と試行回数 Nt(a)、総ステップ数 t を使ってUCB値を計算します。
- 計算されたUCB値が最も高いアームを選択します。
- 選択したアームを実行し、得られた報酬 r を観測します。
- 選択したアームの試行回数 N(a∗) を1増やし、観測した報酬 r を使って報酬の推定値 Q(a∗) を更新します。(新しい平均値を効率的に計算する「増分更新」がよく使われます)
- 繰り返し: このループを繰り返すことで、アルゴリズムは徐々に最適なアームを見つけ出していきます。
UCB方策 vs 他の探索戦略 (ε-greedy)
UCB方策の良さを理解するために、もう一つの代表的な探索戦略であるε-greedy(イプシロン・グリーディ)法と比較してみましょう。
ε-greedy法とは?
ε-greedy法は非常にシンプルで、以下のように動作します。
- 確率 1−ϵ で: 現時点で最も良いと推定される行動(最も平均報酬が高い行動)を選択します(利用)。
- 確率 ϵ で: 現在の推定に関係なく、ランダムにいずれかの行動を選択します(探索)。
ここで、ϵ (イプシロン) は0から1の間の小さな値(例:0.1)で、探索にどれくらいの割合の試行を割り当てるかを決めるパラメータです。
UCBとε-greedyの比較
UCBとε-greedyはどちらも探索と利用のバランスを取ろうとしますが、そのアプローチには大きな違いがあります。
【表1: 探索戦略の比較】
| 特徴 | UCB方策 | ε-greedy法 |
| 探索の仕方 | 不確かさ(試行回数)が大きい行動を優先的に探索 | ランダムに探索 (確率 ϵ) |
| 利用の仕方 | 推定報酬+不確かさボーナスが最大の行動を選択 | 推定報酬が最大の行動を選択 (確率 1−ϵ) |
| 情報活用 | 試行回数や経過時間を考慮して賢く探索 | 探索時は過去の情報を活用しない |
| パラメータ | 探索係数 c (UCB1は c=2 固定が多い) | 探索率 ϵ (調整が必要) |
| 主な利点 | 効率的な探索、理論的な後悔保証 | 実装が非常に容易 |
| 主な欠点 | 計算がやや複雑、環境への仮定あり | 非効率な探索の可能性、ϵ調整が必要 |
主な違いのポイント:
- 探索の賢さ: UCBは「どの選択肢の情報が不足しているか」を考慮して、探索する価値のある行動を優先的に選びます。一方、ε-greedyの探索は完全にランダムなので、既に良くないとわかっている行動や、十分に試した行動を再度探索してしまう可能性があり、非効率になることがあります。
- 理論的保証: UCBには「後悔(Regret)」と呼ばれる指標を理論的に小さくできる(対数オーダーで抑えられる)という強力な数学的裏付けがあります。後悔とは、「もし最初から最適な行動を知っていて、それだけを選び続けた場合の総報酬」と「実際にアルゴリズムが得た総報酬」との差のことで、これが小さいほど効率的に学習できていると言えます。ε-greedyも後悔を抑えられますが、一般的にUCBの方が効率的です。
- パラメータ調整: ε-greedyでは適切な ϵ の値を設定する必要がありますが、これは問題によって異なり、調整が難しい場合があります。UCB1は c=2 を使うことが多く、パラメータ調整の手間が少ない場合があります(ただし、最適な c は問題依存の場合もあります)。
これらの理由から、特に効率的な探索が求められる場面では、UCB方策がε-greedyよりも優れた性能を発揮することが多いです。
UCB方策のメリット・デメリット
どんな手法にも良い点と注意すべき点があります。UCB方策のメリットとデメリットを整理しておきましょう。
メリット
- 効率的な探索と後悔の最小化: UCBの最大の強みです。不確かさを考慮した探索により、無駄な探索を減らし、効率的に最適な選択肢に収束していくことが期待できます。理論的な後悔保証がある点も大きな魅力です。
- 実装の容易さ(基本形): UCB1のような基本的なアルゴリズムは、コンセプトを理解すれば比較的シンプルに実装できます。
- パラメータ調整の手間が少ない(基本形): UCB1では探索パラメータ c を 2 に固定してもうまくいくケースが多く、ε-greedyの ϵ ほど慎重な調整を必要としない場合があります。
デメリットと注意点
- 報酬の仮定: UCBの理論的な保証は、多くの場合、各行動の報酬が特定の範囲内(例: 0から1の間)に収まっていることなどを前提としています。この仮定が成り立たない場合、性能が低下する可能性があります。
- 初期探索コスト: アーム(選択肢)の数が非常に多い場合、初期段階で全てのアームを少なくとも1回試す必要があるため、初期コストがかかることがあります。
- 非定常環境への対応: 標準的なUCBアルゴリズムは、各アームの報酬確率が時間を通じて一定である(定常環境)ことを想定しています。しかし、現実の問題では、ユーザーの好みが変わったり、外部環境が変化したりして、報酬確率が変わること(非定常環境)がよくあります。このような環境では、古い情報に基づいて最適でないアームを選び続けてしまう可能性があるため、標準的なUCBはうまく機能しないことがあります。この場合は、後述するDiscounted UCBなどの発展形を使う必要があります。
UCB方策はどこで使われている? – 具体的な応用例
UCB方策は、その効率性の高さから、様々な分野で実用化されています。
Webサイト最適化 (A/Bテストの進化系)
Webサイトのボタンの色、広告のキャッチコピー、レイアウトなど、複数のデザイン案(A案, B案, C案…)を比較して、どれが最も高いクリック率やコンバージョン率(購入率など)を達成できるかテストしたい場面はよくあります。
従来のA/Bテストでは、各案に均等にアクセスを割り振って比較しますが、効果の低い案にも多くのアクセスが流れ続けるため、機会損失が発生します。
UCBを使うと、初期は各案を均等に試しつつ、データが集まるにつれて効果の高い案へのアクセス割り当てを増やし、効果の低い案への割り当てを減らす、といった動的な最適化が可能です。これにより、テスト期間中の全体の成果を高めながら、最適な案を効率的に見つけることができます。これはバンディットアルゴリズムによるA/Bテストとも呼ばれます。
推薦システム
ECサイトや動画配信サービスなどで、「あなたへのおすすめ」が表示されますよね。これもUCBが活躍する分野です。
- ユーザーが過去に好んだアイテムに似たもの(利用)を推薦しつつ、
- まだユーザーが知らないけれど、潜在的に好みそうな新しいジャンルのアイテム(探索)も時折混ぜて表示する。
このようにUCBを使うことで、ユーザーを飽きさせず、新しい発見を提供しながら、全体的な満足度や利用率を高めることを目指します。
オンライン広告
インターネット広告では、限られた広告枠にどの広告を表示すれば、最もクリックされたり、商品購入に繋がったりするかをリアルタイムで最適化する必要があります。
- 過去にクリック率が高かった広告(利用)を優先的に表示しつつ、
- 新しく入稿された広告や、まだ効果が未知数の広告(探索)の効果も試していく。
UCBを用いることで、広告収益を最大化するための動的な広告配信が可能になります。
その他 (臨床試験、ゲームAIなど)
UCBの応用範囲は広く、以下のような分野でも利用または研究されています。
- 臨床試験: より効果の高い治療法を効率的に見つけ出すために、有望な治療法を多くの患者に適用しつつ、他の治療法のデータも収集する。
- ゲームAI: 将棋や囲碁、ビデオゲームなどで、AIが膨大な選択肢の中から有望な手を探す際に、有望な手の深掘り(利用)と、未知の手の評価(探索)のバランスを取るために、UCBの考え方がモンテカルロ木探索(MCTS)などで利用されています。
- ネットワークルーティング: 通信データをどの経路で送れば遅延が少なくなるか、動的に最適化する。
UCB方策の発展形 – さらに賢く進化
基本的なUCB1アルゴリズム以外にも、特定の課題に対応したり、性能を向上させたりするために、様々な発展形が考案されています。ここでは代表的なものをいくつか紹介します。
UCB1-Tuned
基本的なUCB1では、不確かさボーナスは試行回数のみに依存していました。UCB1-Tunedは、これに加えて報酬のばらつき(分散)も考慮します。報酬のばらつきが大きいアームは、平均値が安定しにくいため、より多くの探索が必要だと判断し、ボーナスを調整します。これにより、特に報酬の変動が大きい場合に、より安定した性能を発揮することがあります。
LinUCB (Linear UCB)
これまでのUCBは、選択肢(アーム)自体しか考慮していませんでした。しかし、多くの実用的な問題では、「どんな状況(文脈)で、どの選択肢を選ぶか」が重要になります。
例えば、推薦システムでは、「どんなユーザー(年齢、性別、過去の購買履歴など)に、どのアイテム(カテゴリ、価格帯など)を推薦するか」といった文脈情報が非常に重要です。
LinUCBは、このような文脈情報 (Context) を活用するUCBの拡張版です。ユーザーの特徴やアイテムの特徴などを数値ベクトル(特徴量)として扱い、報酬がこれらの特徴量の線形結合で近似できると仮定して学習を進めます。これにより、個々のユーザーや状況に合わせた、よりパーソナライズされた探索と利用のバランスを取ることが可能になります。推薦システムやオンライン広告で広く使われている強力な手法です。
その他のバリエーション
- 非定常環境向け: 報酬確率が時間変化する環境に対応するため、過去の情報を徐々に割り引いていくDiscounted UCB (D-UCB) や、直近のデータのみを使うSliding-Window UCB (SW-UCB) などがあります。
- ベイジアンアプローチ: 報酬の確率分布を仮定し、ベイズ統計の枠組みで不確かさを更新していくベイジアンUCBやトンプソンサンプリング (Thompson Sampling) も、UCBと同様に探索と利用のバランスを取るための有力な手法です。
これらの発展形は、より複雑な現実の問題に対応するために研究・開発が進められています。
まとめと次のステップ
今回は、強化学習における重要な探索戦略であるUCB方策について、その基本的な考え方から応用、発展形までを解説しました。
UCB方策のポイント:
- 探索と利用のトレードオフという課題に対する強力なアプローチ。
- 「不確かさに対する楽観主義」に基づき、試行回数が少ない選択肢にボーナスを与える。
- UCB値(推定平均報酬+不確かさボーナス)が最大の行動を選択する。
- ランダムな探索を行うε-greedyと比較して、効率的な探索が可能で、理論的な後悔保証がある。
- Web最適化、推薦システム、オンライン広告など、幅広い分野で実用化されている。
- 文脈情報を扱えるLinUCBや、非定常環境に対応したバリエーションなど、多くの発展形が存在する。
UCB方策は、不確実性の中で限られた情報から最善の意思決定を下すための、非常にエレガントで強力なツールです。この考え方を理解することは、強化学習だけでなく、データに基づいた意思決定を行う上で、きっとあなたの役に立つはずです。
次のステップとして:
- 今回紹介した擬似コードを参考に、簡単なプログラミング言語(Pythonなど)でUCBを実装してみる。
- より詳細な理論や発展形について、専門書や論文を読んでみる。
- 他の強化学習アルゴリズム(Q学習、SARSA、方策勾配法など)についても学んでみる。
強化学習の世界は奥深く、エキサイティングな分野です。この記事が、あなたの学びの第一歩となれば幸いです。
最後までお読みいただき、ありがとうございました!
コメント